Education*
Devops
Architecture
F/B End
B.Chain
Basic
Others
CLOSE
Search For:
Search
BY TAGS
linux
HTTP
golang
flutter
java
fintech
개발환경
kubernetes
network
Docker
devops
database
tutorial
cli
분산시스템
www
블록체인
AWS
system admin
bigdata
보안
금융
msa
mysql
redis
Linux command
dns
javascript
CICD
VPC
FILESYSTEM
S3
NGINX
TCP/IP
ZOOKEEPER
NOSQL
IAC
CLOUD
TERRAFORM
logging
IT용어
Kafka
docker-compose
Dart
Joinc와 함께하는 LLM - vector embedding 기본
Recommanded
Free
YOUTUBE Lecture:
<% selectedImage[1] %>
yundream
2024-06-07
2024-06-07
932
### 소개 벡터 임베딩(vector embedding)는 NLP, 추천 및 검색 알고리즘의 핵심 개념으로 최근 기계학습, LLM 에 널리 채택되고 있다. 소프트웨어 알고리즘은 복잡한 문제를 컴퓨터와 프로그래밍언어를 이용해서 풀어내는 일련의 과정인데, 이런 작업을 위해서는 "숫자"를 사용한다. 숫자를 사용하는 이유는 컴퓨터가 숫자를 처리하는데 특화되었기 때문이다. 그래서 고차원적인 문제를 "숫자"라는 저차원의 데이터로 치환해서 문제를 해결하게 된다. 언어도 마찬가지다. 언어의 처리에서 가장 중요한 것은 "언어의 의미"를 찾아내는 것이다. "의미"는 추상적이고 고차원적인 데이터인데, 벡터 임베딩은 텍스트를 좀 더 쉽게 작업할 수 있도록 숫자의 목록으로 변환해서 처리한다.  벡터 임베딩을 이용해서 인간이 인지하는 의미론적 유사성을 "벡터 공간"에서 표현 할 수 있다. 벡터 공간이라고 하면 헷갈릴 수 있는데, Object들(이를테면 단어)들이 분포된 좌표 공간이라고 보면 된다. 의미적으로 유사한 단어들은 해당 벡터 공간에서 보다 가까이 붙어 있을 건인데, 예를 들오 "king"은 "queen"과 가까이 붙어있을 것이고, "computer"과는 멀리 떨어져 있을 것이다. 즉 이미지, 오디오, 뉴스 기사, 사용자 프로필, 날씨 패턴, 경제정보와 같은 실제 객체와 개념을 벡터 임베딩으로 표현하면, 각 객체와의 의미론적 유사성을 "거리"로 정량화 할 수 있다. 이들은 숫자로 구성되기 때문에, 클러스터링, 추천, 분류와 같은 기계학습에 적합하다. 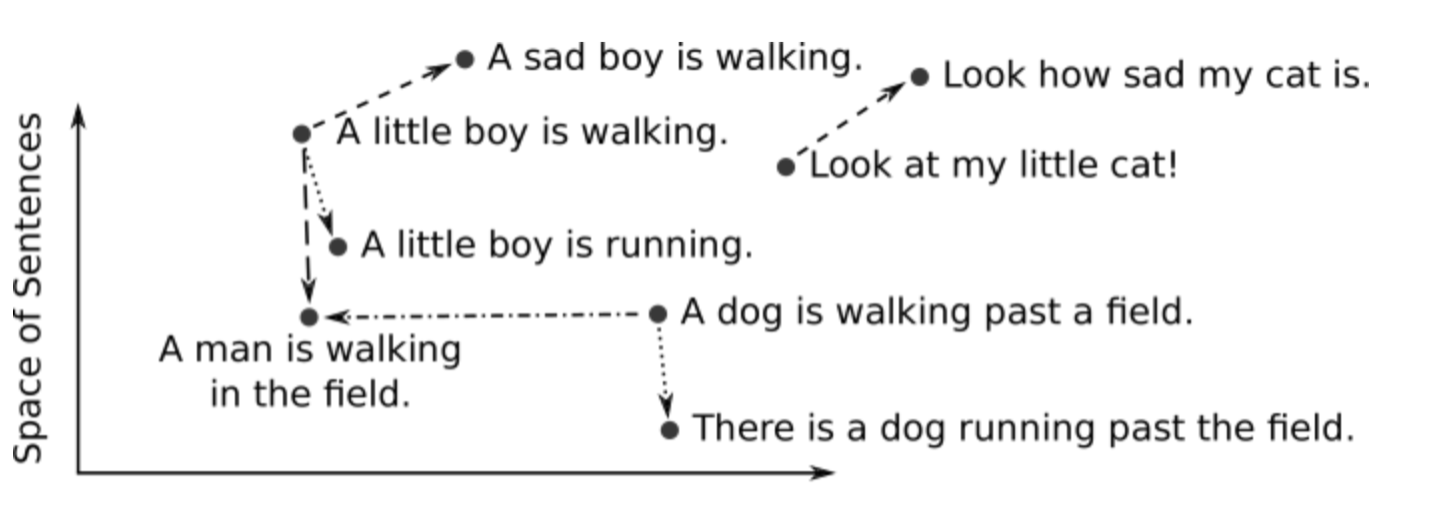 ### 벡터 사이의 거리 앞서 벡터 사이의 거리를 계산하여서 객체간의 유사성을 찾는다고 언급했는데, 문제에 잘 맞는 거리 측정법에 따라서 벡터 공간에서 벡터사이의 거리를 계산 할 수 있다. ML에서 일반적으로 사용하는 거리 측정법으로는 Euclidean, Manhattan, Cosine 및 Chebyshev가 있다.  ### 검색의 수행 벡터 임베딩을 사용하여 객체 사이의 거리를 계산하는 것으로 객체 간의 유사성을 나타낼 수 있다. 여기에서 **벡터 검색** 혹은 **유사성 검색(similarity search)** 가 시작된다. 쿼리가 주어지면 가장 유사한 항목을 찾아야 하는데 이를 K-최근접 이웃(KNN - K Nearest Neighbors)이라고 한다. ##### K Nearest Neighbors K-NN은 주어진 쿼리에 대해서 공간에서 가장 가까운 벡터를 찾는데 널리 사용되는 알고리즘이다. K-NN에서 K는 최근접 **이웃의 수**를 나타내는 하이퍼파라미터다. * K는 각 데이터 포인트의 분류 또는 회귀 값을 결정할 때 고려할 이웃의 수이다. * 영향 * 작은 K: 모델이 데이터에 과적합(overfitting)될 가능성이 크다. 노이즈에 민감해 질 수 있다. * 큰 K: 모델이 데이터에 과소적합(underfitting)될 가능성이 크다. 데이터가 많은 만큼 데이터에 대한 전반적인 패턴을 잘 반영하지만, 세부적인 패턴을 놓칠 수 있다.  ### 벡터 임베딩의 생성 벡터 임베딩을 생성하는 한 가지 방법은 도메인 지식을 사용하여 벡터 값을 엔지니어링 하는 것이다. 이를 **기능 엔지니어링(feature engineering)** 이라고 한다. 예를 들어 의료 데이터의 경우 의료 전문지식을 사용하여 이미지, 텍스트, 영역과 같은 일련의 특징을 정량화 한다. 그러나 엔지니어 벡터 임베딩을 위해서는 도메인지식이 필요하며, 확장하기에 비용이 너무 많이 드는 단점이 있다. 벡터 임베딩을 엔지니어링 하는 대신 객체를 벡터로 변환하도록 모델을 훈련시키는 경우가 많다. 심층 신경망은 이러한 모델을 훈련하기 위한 일반적인 툴이다. Word2Vec, GLoVE, BERT와 같은 모델은 단어, 문장 또는 단락을 벡터 임베딩으로 변환한다. CNN(convolutional neurla networks)과 같은 모델을 이용하여 이미지를 삽입 할 수 있다. CNN의 예로는 VGG 및 Inception이 있다. 오디오의 경우 오디오 주파수의 시각적 표현에(예: Spectrogram) 대한 이미지로 벡터로 변환 할 수 있다. ### 예: CNN을 사용한 이미지 임베딩 0~255까지의 값을 가지는 그레이 이미지가 있다고 가정해보자. 아래 이미지는 0~255까지의 값을 가지는 행렬로 정의 할 수 있을 것이다. 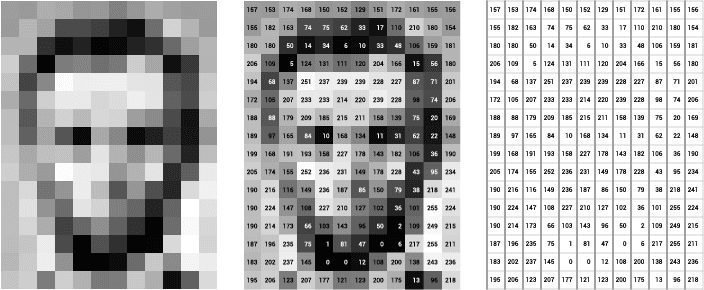 이러한 임베딩은 이미지에서 픽셀 인근의 의미 정보를 유지하는데 유용하다. 하지만 이동, 크기조정, 자르기 등과 같은 이미지 조작 작업과 같은 변화에는 매우 민감하다. 따라서 이러한 임베딩을 학습하기 위한 원시 데이터로 주로 사용한다. CNN 또는 ConvNet(Convolution Neural Network)는 일반적으로 이미지를 임베딩으로 변환하는 시각적 데이터에 사용하는 딥 러닝 아키텍처 클래스다. 아래 이미지는 일반적인 CNN의 구조를 보여준다. 각 레이어의 하위 사각형으로 표시된 수용 필드는 이전 레이어 내의 단일 뉴런에 대한 입력역할을 한다. 또한 서브샘플링 작업은 레이어 크기를 줄이는 반면, 컨볼루션 작업은 레이어 크기를 확장한다. 결과적으로 벡터 임베딩은 funnly connected 레이어를 통해서 수신된다. 이러한 이미지에 대해서 네트워크 가중치(즉, 임베딩 모델)을 학습하려면 대규모의 레이블이 지정된 이미지 세트가 필요하다. 동일한 레이블이 있는 이미지가 다른 레이블이 있는 이미지에 비해서 더 가까운 거리로 삽입되는 방식으로 가중치가 최적화 된다. CNN 임베딩 모델을 학습하면 이미지를 벡터로 변환하고 K-Nearest-Neighbor 인덱스에 저장할 수 있다. 이제 새로운 이미지가 주어지면 이를 CNN 모델로 변환하고 k-most similar 벡터를 검색하여 유사 이미지를 검색할 수 있다. ### 벡터 임베딩 사용 임베딩을 이용하면 객체를 처리 가능한 숫자를 포함한 밀집된 벡터로 나타낼 수 있는데 광범위한 ML 애플리케이션 개발에 유용하게 사용할 수 있다. **Similarity search**는 가장 널리 사용되는 벡터 임베딩 구현 중 하나다. KNN 및 ANN과 같은 검색 알고리즘에서는 유사성을 확인하기 위해 벡터간의 거리를 계산해야 하는데, 벡터 임베딩을 사용하여 거리를 계산 할 수 있다. 가장 가까운 이웃에 대한 검색은 중복 제거, 권장 사항, 이상 탐지, 역 이미지 검색 등과 같은 작업에 사용 할 수 있다. ### 벡터 데이터베이스 벡터 임베딩은 결국 유사도(가까운 거리에 있는 객체)를 검색하기 위한 목적이므로 벡터 정보를 저장하기 위한 데이터베이스가 필요하다. 이를 **벡터 데이터베이스**라고 한다. 벡터 데이터베이스는 ML, AI 애플리케이션 특히 유사도 검색 및 최근접 이웃 탐색(Nearest Neighbor Search)에 많이 사용하고 있다. 벡터 테이터베이스는 아래 목적으로 널리 사용하고 있다. 1. 이미지 검색: 이미지의 특정 벡터를 저장하고, 유사한 이미지를 검색하는데 사용한다. 2. 추천 시스템: 사용자와 아이템을 벡터로 표현하여 유사한 사용자 또는 아이템을 추천하는데 사용한다. 3. 자연어 처리: Word2Vec, BERT 등을 저장하고 유사한 문장이나 단어를 검색하는데 사용한다. 4. 음성 인식 및 처리: 음성 데이터의 벡터를 저장하고 유사한 음성 클립을 검색하는데 사용한다. 벡터 데이터베이스의 중요 기술은 아래와 같다. * HNSW(Hierarchical Navigable Small World)그래프 * LSH(Locality sensitive Hashing) & Sketching * PQ(Product Quantization) * Inverted Files 아래 그림은 벡터 데이터베이스의 작동 방식을 묘사하고 있다. 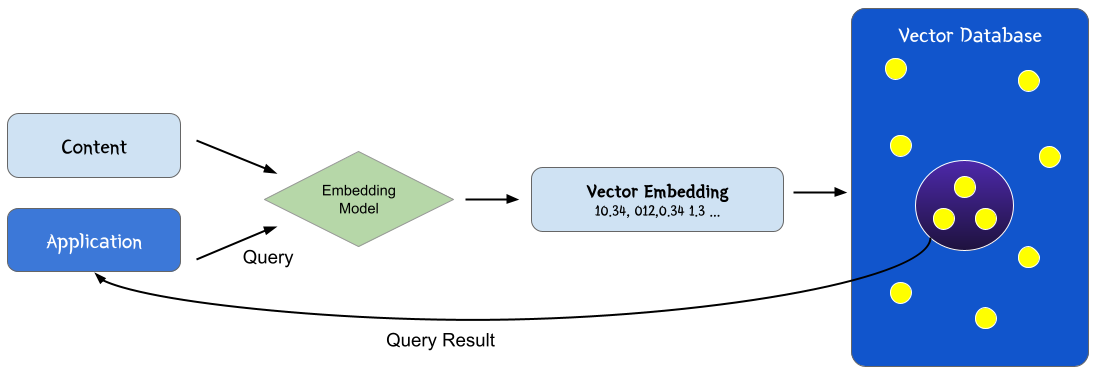 1. 임베딩 모델을 사용해서 인덱싱하려는 콘텐츠에 대한 벡터 임베딩을 만든다. 2. 벡터 임베딩은 원본 콘텐츠에 대한 참조 데이터와 함께 벡터 데이터베이스에 삽입된다. 3. 애플리케이션이 쿼리를 실행하면 동일한 임베딩 모델을 사용해서 쿼리에 대한 임베딩을 생성하고 유사한 벡터 임베딩에 대해서 데이터베이스를 쿼리한다. 그리고 쿼리된 벡터에 사용된 원본 콘텐츠가 함께 리턴된다. ### 벡터 데이터베이스의 작동 방식 우리는 전통적인 (MySQL 같은)데이터베이스가 어떻게 작동하는지는 어느 정도 알고 있다. 즉 문자열, 숫자 및 기타 다양한 유형의 스칼라 데이터를 행과 열에 저장한다. 반면에 벡터 데이터베이스는 "벡터"에서 작동하기 때문에 최적화와 쿼리 방식이 상당히 다르다. * 기존 데이터베이스는 일반적으로 값이 쿼리와 정확히 일치하는 행을 쿼리한다. * 벡터 데이터베이스에서는 쿼리와 가장 유사한 벡터를 찾는다. 이러한 특징을 벡터 데이터베이스는 "정확성"과 "속도"사이에 절충점을 찾아야 한다. 결과가 정확할 수록 쿼리가 느리고 쿼리가 빠를 수록 결과가 부정확할 수 있다. 벡터 데이터베이스의 일반적인 파이프라인은 아래와 같다.  1. **인덱싱**: PQ, LSH, HNSW와 같은 알고리즘을 사용하여 벡터를 인덱싱한다. 2. **쿼리**: 벡터 데이터베이스는 인덱싱된 쿼리 벡터를 기존에 인덱싱된 벡터와 비교하여 가장 가까운 이웃을 찾는다. 3. **포스트 프로세싱**: 데이터 세트에서 최근접 이웃을 검색하고 이를 사후 처리하여 최종 결과를 반환한다. 이 단계에서는 결과물의 순위를 다시 매기는 등의 작업이 포함될 수 있다. ### 벡터 데이터베이스와 LLM과의 관계  LLM에서 벡터 데이터베이스를 이용해서 할 수 있는 것들을 살펴보자. **RAG** 기업은 **RAG(Retrieval Augmented Generation)** 라고 부르는 기술을 이용해서 기업의 "컨텍스트"를 제공한다. 컨텍스트는 사용자 메뉴얼, 사용자의 물건 구매내역, 신문기사, 코드 등이 될 수 있다. 기업은 벡터 데이터베이스를 이용해서 LLM의 지식을 확장 할 수 있다. 임베딩과 LLM을 결합할 경우 아래와 같은 작업을 할 수 있다. 1. 질문은 LLM의 임베딩으로 변환된다. 2. 임베딩은 벡터 테이터베이스에서 관련 컨텍스트(문서, 이미지등)을 검색하는데 사용된다. 3. 이 컨텍스트의 도움으로 LLM 프롬프트가 생성된다. 4. 응답이 생성된다. 기업이 가지고 있는 컨텍스트를 기반으로 응답이 만들어지기 때문에 정확한 결과를 제공 할 수 있다. **LLM 메모리 역할** 여러 사용자가 동시에 LLM 애플리케이션을 사용 할 경우 사용자와의 세션관리가 중요해진다. 벡터 데이터베이스는 데이터베이스로 작동하기 때문에, 전체 채팅 기록에서 현재 메시지와 관련된 N개 메시지를 검색하는데 도움이 된다. 이를 이용하면 사용자의 세션을 관리 할 수 있을 뿐 아니라, 유사한 질문을 검색할 수 있으므로 LLM의 컨텍스트 길이(토큰)제한을 우회할 수 있으며 성능 최적화도 가능하다. 1. 사용자가 쿼리를 요청한다. 2. 시스템은 벡터 데이터베이스에 저장된 임베딩을 검색하여 LLM 쿼리에 전달한다. 3. 응답이 사용자에게 전달된다. 또한 응답 임베딩(로그 포함)이 벡터 데이터베이스에 저장된다. **LLM 쿼리 및 응답의 캐시** 쿼리가 실행되면 LLM을 호출하기 전에 임베딩을 생성하고 캐시를 먼저 조회한다. 이를 통해 LLM의 사용성과 응답성을 개선 할 수 있다. 1. 사용자가 질문을 한다. 2. 임베딩이 생성되고 캐시 조회가 수행된다. 3. 캐시에 정보가 있으면 응답이 제공된다. LLM이 호출되지 않는다. 4. 캐시에 정보가 없을 경우 LLM이 호출되고 응답이 캐시에 저장된다. ### 주요 벡터 데이터베이스 | Name | License | | ---------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------- | | [AllegroGraph](https://en.wikipedia.org/wiki/AllegroGraph "AllegroGraph") | Proprietary (Managed Service) | | [Apache Cassandra](https://en.wikipedia.org/wiki/Apache_Cassandra "Apache Cassandra") | [Apache License 2.0](https://en.wikipedia.org/wiki/Apache_License_2.0 "Apache License 2.0") | | Chroma | [Apache License 2.0](https://en.wikipedia.org/wiki/Apache_License_2.0 "Apache License 2.0") | | [Azure Cosmos DB](https://en.wikipedia.org/wiki/Cosmos_DB "Cosmos DB") | Proprietary (Managed Service) | | [Couchbase](https://en.wikipedia.org/wiki/Couchbase "Couchbase") | [BSL 1.1](https://en.wikipedia.org/wiki/Business_Source_License "Business Source License") | | [Elasticsearch](https://en.wikipedia.org/wiki/Elasticsearch "Elasticsearch") | [Server Side Public License](https://en.wikipedia.org/wiki/Server_Side_Public_License) | | [HDF5](https://en.wikipedia.org/wiki/HDF5 "HDF5") Query Indexing[[22]](https://en.wikipedia.org/wiki/Vector_database#cite_note-22) | [BSD 3-Clause](https://en.wikipedia.org/wiki/BSD_3-Clause "BSD 3-Clause") | | Lantern | [BSL 1.1](https://en.wikipedia.org/wiki/Business_Source_License "Business Source License") | | LlamaIndex | [MIT License](https://en.wikipedia.org/wiki/MIT_License "MIT License") | | Milvus | [Apache License 2.0](https://en.wikipedia.org/wiki/Apache_License_2.0 "Apache License 2.0") | | [MongoDB](https://en.wikipedia.org/wiki/MongoDB "MongoDB") | [Server Side Public License](https://en.wikipedia.org/wiki/Server_Side_Public_License "Server Side Public License") (Managed service) | | [Neo4j](https://en.wikipedia.org/wiki/Neo4j "Neo4j")[[31]](https://en.wikipedia.org/wiki/Vector_database#cite_note-31) | [GPL v3](https://en.wikipedia.org/wiki/GPL_v3 "GPL v3") (Community Edition) | | [OpenSearch](https://en.wikipedia.org/wiki/OpenSearch_(software) "OpenSearch (software)") | [Apache License 2.0](https://en.wikipedia.org/wiki/Apache_License_2.0 "Apache License 2.0") | | Pinecone | Proprietary (Managed Service) | | [Postgres](https://en.wikipedia.org/wiki/Postgres "Postgres") with pgvector | PostgreSQL License | | Qdrant | [Apache License 2.0](https://en.wikipedia.org/wiki/Apache_License_2.0 "Apache License 2.0") | | [Redis](https://en.wikipedia.org/wiki/Redis "Redis") Stack | [Redis Source Available License](https://redis.io/docs/about/license/) | | Snowflake | Proprietary (Managed Service) | | [SurrealDB](https://en.wikipedia.org/wiki/SurrealDB "SurrealDB") | [BSL 1.1](https://en.wikipedia.org/wiki/Business_Source_License "Business Source License") | | Vespa | [Apache License 2.0](https://en.wikipedia.org/wiki/Apache_License_2.0 "Apache License 2.0") | | Weaviate | [BSD 3-Clause](https://en.wikipedia.org/wiki/BSD_3-Clause "BSD 3-Clause") | ### Vector space model 과의 차이 임베딩 모델과 벡터 스페이스 모델은 자연어 처리 정보 검색에서 많이 사용하는 기법들이다. 둘 다 단어 혹은 문서를 벡터 공간에 표현하지만 방법에 있어서 차이가 있다. ##### 유사점 * 벡터 표현: 둘 다 단어 또는 문서를 벡터로 표현한다. 이는 수치 공간에서 표현하기 때문에 계산이 용이하다. * 유사도 계산: 두 모델 모두 벡터 간의 유사도를 계산하여서 단어 또는 문서 간의 관련성을 평가한다. 일반적으로 코사인 유사도, 유클리디안 거리 등을 사용한다. * 차원축소 가능: 차원이 높은 데이터를 처리할 때, PCA, SVD 등 차원 축소 기법을 사용하여 처리 효율을 높일 수 있다. ##### 차이점 * 학습 방식 * 임베딩 모델: Word2Vec, GloVe, FastText 등의 모델을 사용하며 대규모 텍스트 코퍼스를 사용하여 단어의 의미적 관계를 학습한다. 단어의 문맥정보를 활용하여 고차원의 밀집 벡터를 생성한다. * 벡터 스페이스 모델: TF-IDF, Count Vectorizer 등은 주로 문서 내 단어의 빈도 정보를 기반으로 벡터를 생성한다. 통계적 접근 방법을 사용하여 각 단어 또는 문서의 가중치를 계산한다. * 벡터 밀도 * 임베딩 모델: 밀집 벡터(Dense Vector)를 사용한다. 각 단어는 보통 100-300 차원 정도의 밀집된 벡터로 표현된다. * 벡터 스페이스 모델: 희소 벡터(Sparse Vector)를 사용한다. 예를 들어 TF-IDF 벡터의 경우 고차원의 희소 행렬로 표현되는데 대부분의 값이 0이다. * 문맥 반영 * 임베딩 모델: 문맥을 반영한 단어 벡터를 생성한다. 예를 들어"bank"라는 단어는 금융과 강이라는 맥락에서 다른 벡터로 표현될 수 있다. * 벡터 스페이스 모델: 문맥을 직접적으로 반영하지 않으며, 빈도만을 고려한다. * 사전 훈련 여부 * 임베딩 모델: 대규모 텍스트 코퍼스에서 미리 훈련된 벡터를 사용할 수 있다. 예를 들어, 사전 훈련된 Word2Vec 또는 GloVe 벡터를 다운로드하여 사용할 수 있다. * 벡터스페이스 모델: 일반적으로 주어진 코퍼스에 대해 직접 벡터를 생성한다. * 확장성 * 임베딩 모델: 특정 도메인 또는 어휘에 대해 추가 훈련을 해야 할 수 있다. 새로운 단어나 문맥이 포함된 데이터를 추가로 학습해야 한다. * 벡터 스페이스 모델: 새로운 문서나 단어가 추가될 때 비교적 간단하게 업데이트 할 수 있다. ### 참고 * [Vector database](https://www.pinecone.io/learn/vector-database/) * [3 ways vector databases take your llm use case next level mishra](https://www.linkedin.com/pulse/3-ways-vector-databases-take-your-llm-use-cases-next-level-mishra/)
Recent Posts
Vertex Gemini 기반 AI 에이전트 개발 06. LLM Native Application 개발
최신 경량 LLM Gemma 3 테스트
MLOps with Joinc - Kubeflow 설치
Vertex Gemini 기반 AI 에이전트 개발 05. 첫 번째 LLM 애플리케이션 개발
LLama-3.2-Vision 테스트
Vertex Gemini 기반 AI 에이전트 개발 04. 프롬프트 엔지니어링
Vertex Gemini 기반 AI 에이전트 개발 03. Vertex AI Gemini 둘러보기
Vertex Gemini 기반 AI 에이전트 개발 02. 생성 AI에 대해서
Vertex Gemini 기반 AI 에이전트 개발 01. 소개
Vertex Gemini 기반 AI 에이전트 개발-소개
Archive Posts
Tags
AI
database
Joinc와 함께하는 LLM
LLM
Copyrights © -
Joinc
, All Rights Reserved.
Inherited From -
Yundream
Rebranded By -
Joonphil
Recent Posts
Archive Posts
Tags