Education*
Devops
Architecture
F/B End
B.Chain
Basic
Others
CLOSE
Search For:
Search
BY TAGS
linux
HTTP
golang
flutter
java
fintech
개발환경
kubernetes
network
Docker
devops
database
tutorial
cli
분산시스템
www
블록체인
AWS
system admin
bigdata
보안
금융
msa
mysql
redis
Linux command
dns
javascript
CICD
VPC
FILESYSTEM
S3
NGINX
TCP/IP
ZOOKEEPER
NOSQL
IAC
CLOUD
TERRAFORM
logging
IT용어
Kafka
docker-compose
Dart
시스템 디자인 가이드
Recommanded
Free
YOUTUBE Lecture:
<% selectedImage[1] %>
yundream
2023-02-23
2023-02-23
18748
## 왜 시스템 아키텍처를 배워야 하는가 ? 지난 20년간 웹 애플리케이션은 엄청난 성장을 이루어냈다. 수십억면의 사용자들이 웹 애플리케이션을 사용하고 있으며, 산업 그리고 부의 판도도 뒤집어 버렸다. 우리는 거의 Kakao, Naver, Twitter, Facebook, Google, Instagram 등의 서비스를 사용하고 있다. 이들 서비스는 동시에 수백만에서 수천만의 사용자가 사용하기 때문에 대량의 트래픽을 처리해야 하며, 확장 가능하도록 시스템을 설계해야 한다. 경력의 초기에는 단위 컴포넌트를 개발하고 최적화 하는데, 집중하겠으나 경력을 쌓을 수록 시스템 아키텍처에 대한 이해가 필요해진다. 왜냐하면 경력이 올라갈수록 자연스럽게 전체 시스템에 대한 최적화 능력을 자연스럽게 요청하기 때문이다. 전체 시스템이 유기적으로 작동하게 하려면 컴포넌트 최적화와는 다른 기술 / 마인드 셋을 가져야 한다. 기술의 수평적 확장보다는 하나의 기술을 깊이 파는데 관심이 가진 경우도 있을 것이다. 하지만 그렇다고 하더라도 경력이 늘어날 수록 다른 팀과의 커뮤니케이션을 요구하게 되게, 결국 지식의 수평적인 확장이 어느 정도 필요해 진다. 문제를 시스템 관점에서 바라보는 기술과 마인드 셋은 훈련을 통해서 성장시켜나가야 하므로, 초기 단계 부터 학습이 필요하다. ### 시스템 아키텍처 무엇인가 ? 컴퓨터 시스템은 비즈니스 문제를 풀기 위해서 존재한다. 시스템 아키텍처는 이 문제를 풀기위한 시스템 모듈, 구성요소, 인터페이스, 데이터, 저장소와 같은 **시스템 요소와 이들의 관계를 정의하는 프로세스**이다. ## 시스템 설계의 기초 시스템을 설계할 때 고려해야할 기본 사항은 다음과 같다. * 요구사항의 수집 : 해결해야 할 문제와 시스템 요구사항을 이해한다. * 확장성 : 시간이 지남에 따라 증가하는 수요를 처리하기 위해서 시스템을 확장하거나 수정할 수 있는 방법을 고려한다. * 성능 : 시스템의 응답 시간, 처리량 및 용량 요구사항을 결정한다. * 가용성 : 구성요소에 장애가 발생하더라도 계속 작동할 수 있도록 고가용성으로 설계한다. * 보안 : 중요한 데이터를 보호하기 위한 적절한 조치를 구현한다. * 모듈성 : 시스템을 더 작은 모듈로 분해하여 개발, 유지/보수 및 테스트를 단순화 한다. * 테스트 : 시스템이 요구사항을 충족하고 요구사항대로 작동하는지 확인하기 위해서 테스트를 계획하고 구현한다. * 유지관리 : 시스템의 지속적인 유지 관리 및 지원 요구사항을 확인하여, 쉽게 유지관리 및 업그레이드 할 수 있도록 설계한다. 시스템 설계는 성공적인 서비스를 위해서 서비스 요구사항 분석에서 용량산정, 테스트, 운영까지의 모든 단계에서 각 요소를 신중하게 고려해야 한다. 따라스 아키텍트는 서비스에 대한 이해부터 시작해서, 보안/운영/기획/개발/인프라 팀과의 관계를 구축하고 광범위한 기술과 솔류션에 대한 지식을 가지고 있어야 한다. ### 수평 확장과 수직 확장 **확장성**은 대기시간을 최소화하면서 사용자의 늘어난 트래픽을 처리하고 견딜 수 있는 애플리케이션 기능이다. 사용자의 늘어난 트래픽을 처리하려면 애플리케이션이 잘 확장될 수 있도록 시스템을 구성해야 한다. 애플리케이션이 확장하는 두 가지 방법은 수평확장(Horiozntal scaling)과 수직확장(Vertical scaling)이다. 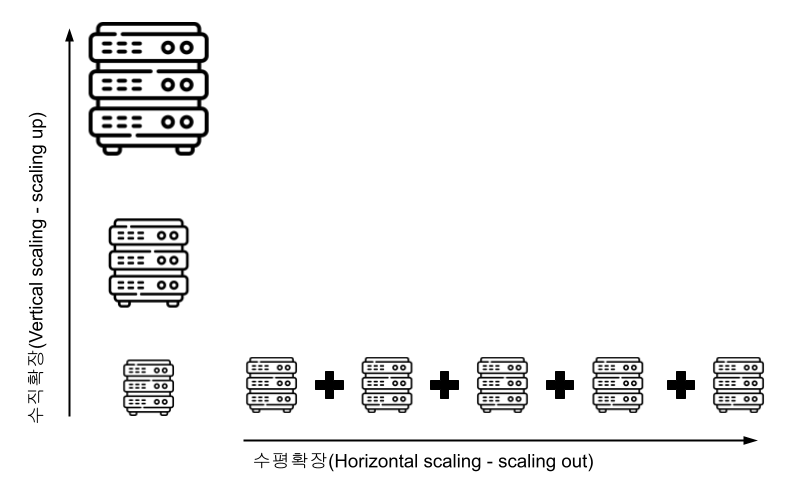 수평확장은 더 많은 서버를 추가 투입하는 방식이다. 수직확장은 단일 서버에 더 강력한 CPU, 더 빠르고 많은 메모리를 투입하여 단일 서버의 능력을 높이는 방식이다. 각각의 장/단점이 있는데, 일반적으로 수평적 확장은 **많은 양의 트래픽**을 처리 해야 하는 분산 시스템에 더 적합하고 수직적 확장은 **많은 양의 데이터**를 처리하거나 복잡한 계산을 수행하는 시스템에 더 적합하다. 소셜 네트워크 서비스의 경우, 웹 서비스 영역은 많은 양의 트래픽을 처리해야 하기 때문에 수평확장이 고객의 데이터를 처리해야 하는 영역은 수직확장이 적당할 것이다. 물론 현실에서는 두 개의 기술을 모두 섞어쓰는게 일반적이다. 데이터처리하는 영역의 경우 수직확장을 우선으로 하되, 수형확장도 함께 고려하여서 운영의 유연성과 비용을 함께 관리한다. ### Proxy 서버 프록시(Proxy)서버는 사용자와 인터넷 간의 게이트웨이 역할을 한다. 핵심 목표는 웹 사이트와 사용자를 분리하는데 있다. 프록시 서버는 아래의 이점을 제공한다. * 보안성 향성 : 인터넷 사용자의 요청이 서버로 직접 전달되는 대신에, 중간에서 한번 더 처리를 하기 때문에 보안성을 향상시킬 수 있다. * 요청에 대한 응답속도를 높이기 위한 캐시 데이터의 관리 : HTML, CSS, Javascript, 자주 요청하는 이미지, 영상, 데이터 등을 프록시 서버에 캐시해 두고 서비스 할 수 있다. * 직원 및 자녀의 인터넷 사용 통제 * 차단된 리소스에 대한 접근 프록시는 트래픽의 방향에 따라서 정방향 프록시(forward proxy)와 역방향 프록시(reverse proxy)가 있다. 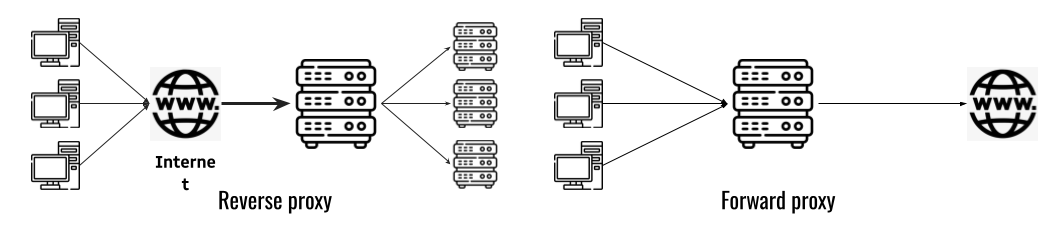 역방향 프록시는 사용자의 요청을 받아서 서버로 전달하며, 정방향 프락시는 사용자의 요청을 받아서 인터넷으로 보내는 역할을 한다. 서버 개발자, 클라우드 엔지니어는 거의 대부분 역방향 프록시를 다룬다. 예를들어 로드밸런서도 역방향 프록시의 일종이다. ### Redundancy 와 Replication Redundancy(중복성)는 시스템의 안정성과 성능을 높이기 위해서 시스템의 **중요 구성 요소를 복제**하는 프로세스다. 일반적으로 백업 혹은 복구장치(안전장치)의 형태로 제공된다. Redundancy는 단일 실패지점을 제거하여서 시스템이 안정적으로 작동하게 하는 중요한 역할을 한다. 프로덕션 환경의 경우 2개 이상의 동일한 기능을 가진 서버로 구성하여, 하나의 서버에 문제가 생길 경우 장애조치(failover)하여 다른 서버가 계속 해서 작업을 할 수 있게 한다. 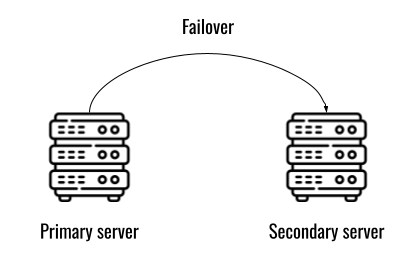 Replication(복제)는 Redundancy된 리소스간의 일관성을 보장하기 위해서 정보를 공유하는 프로세스다. Primary Server에 문제가 생겨서 Secondary Server가 작업을 대신하는데, 두 개 서버간 데이터가 일치하지 않는다면 서비스에 문제가 생길 것이다. 복제는 많은 DBMS에서 사용되는데, 원본 데이터를 다른 서버에 업데이트하여 두 개 서버간의 데이터를 동기화한다. 이렇게 하여 애플리케이션의 안정성, 내결함성, 접근성을 개선 할 수 있다.  ## 블록 스토리지 블록 스토리지(Block Storage)는 동일한 크기의 연속된 블록에 데이터를 나누어서 저장하는 기술이다. 각 블록에는 유일한 식별자가 부여되어서, 원하는 블록에 빠르게 접근 할 수 있다. 흔히 말하는 HDD, SSD가 대표적인 블록 스토리지 저장소다. 데이터는 어떤 블록에든지 저장 할 수 있기 때문에 리소스를 보다 효율적으로 사용 할 수 있다. 블록 스토리지는 일반적인 운영 체제에 의해 제어되며 iSCSI, Fibre Channel, FCoE(Fibre Channel over Ethernet)와 같은 프로토콜로 액세스한다. 블록 스토리지는 일관적인 입출력 성능과 짧은 대기시간등으로 데이터베이스와 같은 고성능 미션 크리티컬 애플리케이션에 주로 사용한다. 온-프레미스 시절에는 개발자는 물론이고 인프라 엔지니어라고 하더라도 스토리지 담당자가 아닌한 블록 스토리지에대해서는 그냥 "하드디스크"정도로만 알고 있어도 문제될건 없었다. 하지만 클라우드 환경에서는 누구나 쉽게 블록 스토리지를 제어 할 수 있게 되면서, 블록 스토리지에 대한 어느 정도의 지식도 필요하게 된다. 어떤 타입의 블록스토리지라도 버튼 클릭 한번으로 사용 할 수 있게 되다보니, 블록 스토리지에 대한 지식의 파급력이 커진결과이다. ## 객체 스토리지 객체 스토리지(Object Storage)는 대량의 비정형 데이터를 저장하고 읽기 위해서 설계된 스토리지다. 파일 단위로 저장하고 읽는 FTP를 생각하면 된다. 파일단위로 저장하기 때문에 동적 확장성을 제공하기가 매우 쉽다는 장점이 있다. 객체 스토리지는 추상화된 스토리지이기 때문에 운영 체제에서 직접 액세스 할 수 없다. 일반적으로는 객체 스토리지를 관리하기 위한 소프트웨어를 통해서 관리한다. 예를 들어 AWS의 대표적인 객체 스토리지인 **S3**는 RESTFul API를 이용해서 파일에 액세스 할 수 있다. 객체 스토리지는 거의 무한대대로 공간을 확대시킬 수 있기 때문에 백업, 비정형 데이터, 로그 파일등의 저장에 특히 널리 사용한다. 객체 데이터는 대량의 비디오, 오디오, 이미지를 관리하는 서비스에서 널리 사용되는데, 아래와 같은 장점으로 **데이터 레이크(Date Lake)** 로의 구축이 늘었다. 1. 확장성 : 객체 스토리지는 무제한의 확장성을 제공한다. 데이터가 크게 늘어난 요즘에 이는 매우 중요한 장점이다. 2. 비용 효율성 : 객체 스토리지는 다른 스토리지보다 훨씬 저렴하므로 많은 양의 데이터를 저장하는데 도움이 된다. 3. 내구성 : 객체 스토리지는 99.9999% 이상의 높은 내구성을 제공하도록 설계되어 있어서 대량의 데이터를 안정적으로 저장할 수 있다. 4. 손쉬운 통합 : 객체 스토리지는 API로 파일을 읽고 저장할 수 있기 때문에 데이터 저장 및 데이터 분석도구와 쉽게 통합된다. ## RAID RAID(Redundant array of independent disks) 앞서 다뤘던 Redundant라는 단어에 주목하자. RAID는 독립된 디스크들을 묶어서 중복성(Redundant)를 부여하여, 데이터를 보호한다. 간단히 말해서 동일한 데이터를 여러개의 서로다른 HDD 혹은 SSD에 저장하여서 드라이브의 장애에도 데이터를 보호할 수 있도록 만든 시스템이다. RAID는 **Redundant**를 달성하는 방법에 따라서 여러단계의 RAID 수준을 가질 수 있다. 표준적인 RAID 수준은 7단계로 RAID 0, RAID 1, RAID 2, RAID 3, RAID 4, RAID 5, RAID 6이 있다. 그리고 각 RAID를 중첩한 RAID 10(RAID 1 + 0), RAID 03(RAID 0+3), RAID 50(RAID 5+0)이 있다. RAID는 응용이기디 때문에, 이 외에도 비표준 RAID 수준도 존재한다. 일반적으로 RAID 0 ~ RAID 6까지 알고 있으면 된다. 소프트웨어 엔지니어는 RAID라는 것이 있다는 정도만 알고 있으면 되며, DevOps 및 클라우드 엔지니어라고 하더라도 굳이 외우고 있을 필요는 없다. **RAID 0** 이 구성에서는 **striping**만 있으며 데이터 중복은 없다. striping은 두 개 이상의 디스크를 묶어서 데이터를 나눠서 저장하는 방식이다. 여러 개의 디스크에 동시에 읽고 쓸 수 있기 때문에 성능을 높이고자 할 때 주로 사용한다. 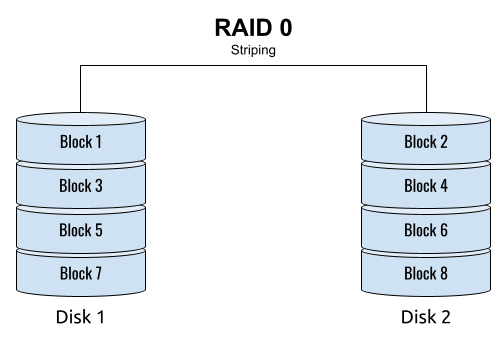 **RAID 1** 은 디스크 미러링 (Disk mirroing)이라고 하는데, 데이터를 다른 드라이브에 복제할 수 있도록 구성된다. 두 디스크에 데이터가 중복되어서 저장되기 때문에 디스크 하나에 문제가 생겨도 데이터를 보호 할 수 있다. 또한 두개의 디스크에서 동시에 읽을 수 있기 때문에 읽기 성능 향상도 기대할 수 있다. 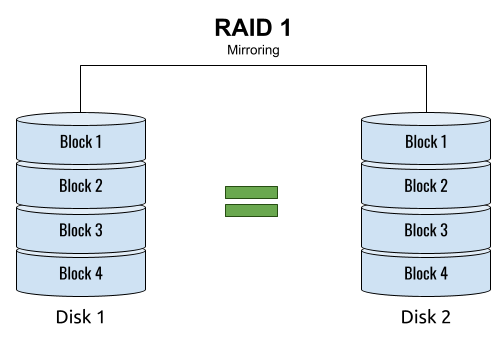 **RAID 2** 데이터 기록용 저장공간과 복구용 저장공간을 별도로 분리하여 구성한다. 복구용 데이터를 저장하기 위해서 많은 공간이 사용되기 때문에 효율성이 떨어진다. 이런 이유로 최근에는 거의 사용하지 않는 방식이다. Striping 방식을 사용하고 있으며, Hamming Code를 이용해서 에러를 체크하고 수정할 수 있다. 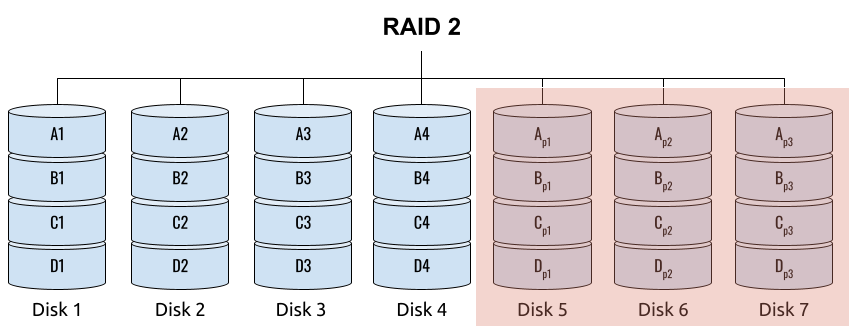 **RAID 3**는 전용의 pairty 디스크가 있는 바이트 수준의 striping으로 구성된다. 단일 데이터 블록이 모든 디스크의 동일한 위치에 저장되기 때문에 일반적으로 여러요청을 도시에 처리하기가 어렵다. 따라서 압축되지 않은 비디오 편집과 같이 긴 연속적인 읽기 및 쓰기등 높은 전송속도를 요구하는 애플리케이션에 적당하다. 임의의 디스크 위치에서 작은 읽기 및 쓰기를 수행하는 응용프로그램에는 최악이다. 실제로는 거의 사용하지 않는 RAID 방식이다. **RAID 4** 전용의 parity 디스크가 있는 블록 수준의 striping으로 구성된다. Striping을 제공하기 때문에 임의 읽기(random read)에서 우수한 성능을 제공한다. 하지만 단일 parity 디스크를 사용하기 때문에 임의 쓰기(random write)의 성능이 떨어진다. 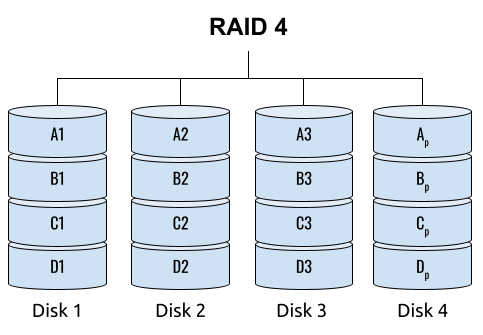 **RAID 5** 는 블록 수준의 striping과 parity로 구성된다. 분산(distributed) parity로 구성된다는 점을 제외하면 RAID 4와 동일하다. 단일 디스크에 오류가 발생해도 분산된 parity를 이용해서 읽기를 계속 할 수 있다. RAID 5는 최소 4개의 디스크가 필요하다. 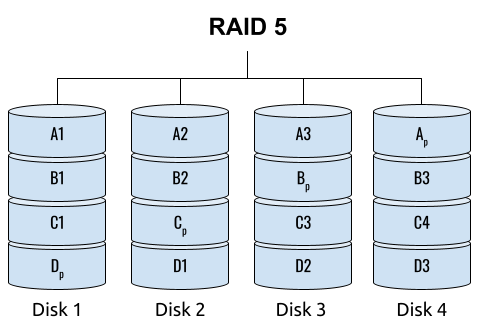 **RAID 6** 는 블록 수준의 striping과 분산 parity로 구성된다. 1개가 아닌 2개의 parity로 구성된다는 점을 제외하면 RAID 5와 동일하다. parity가 2개이기 때문에 2개의 디스크에 문제가 생기더라도 읽기를 계속 할 수 있다. RAID 6는 최소 5개의 디스크가 필요하다. 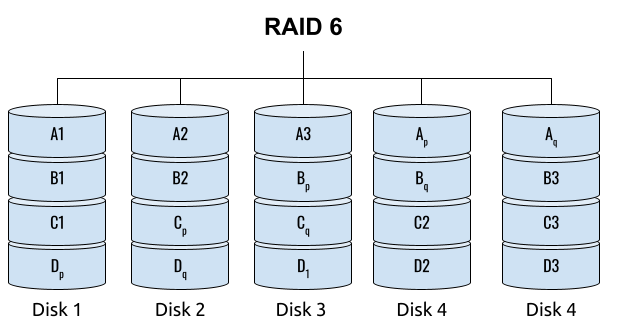 ## Message Queue 메시지 큐(Message Queue)는 발신자로 부터 수신자로 메시지를 라우팅하는 대기열이다. 메시지큐는 먼저 보낸 메시지가 먼저 전달되는 FIFO(선입선출) 정책을 따른다. 메시지큐는 메시지의 수신과 메시지의 처리를 분리해서 처리 할 수 있는 **비동기적인 작업**처리 시스템을 만들기 위해서 널리 사용한다. 메시지를 수신과 메시지의 처리가 분리되기 때문에 수신측은 작업을 방해하지 않고 계속해서 메시지를 수신 할 수 있다. 또한 메시지 큐는 메시지에 대한 임시 저장소 역할을 하기 때문에 데이터에 대한 가용성을 높이며 그 자체가 데이터베이스의 역할을 수행하도록 할 수 있다. 가장 널리 알려진 메시지큐는 Kafak, RabbitMQ, NATS 등이 있다. **Apache Kafaka**는 실시간 데이터 파이프라인 및 스트리밍 애플리케이션을 구축하는데 사용하는 분산 스트리밍 플랫폼이다. Publish-Subscribe 메시징 시스템으로 대량의 시스템을 빠르게 처리하는 것을 주요 목표로 한다. 로그 집계, 실시간 데이터 통합 및 스트림 처리에 널리 사용한다. **RabbitMQ**는 AMQP(Advanced Message Queuing Protocol)로 만들어진 오픈소스 메시지 브로커 소프트웨어다. STOMP, MQTT 및 HTTP 등 다양한 프로토콜을 지원하고 있다. 마이크로 서비스 아키텍처에 널리 사용되며, Publish-Subscribe 메시징 모델 외에도 Request-Response와 같은 다양한 메시징 패턴을 지원한다. **NATS**는 가볍고 쉽게 설치 및 운용하는 것을 목표로 설계된 오픈소스 메시징 시스템이다. 실제 Kafka나 RabbitMQ에 비해서 매우 가볍고 빠르며 설치가 쉬운것이 특장점인 시스템이다. 이들의 차이점은 아래와 같다. * Kafaka는 스트림 처리, 이벤트 소싱 및 로그 집계에 가장 적합하다. * RabbitMQ는 분산 프로세스 간에 안정적인 통신이 필요한 시스템에 적합하다. * NATS는 사용편의성, 고성능 및 낮은 대기시간이 필요한 마이크로 서비스 아키텍처와 같은 분산시스템 구축에 적합하다. ## Consistent Hasing Consistent Hashing은 데이터를 물리적 노드에 맵핑하기 위해서 널리 사용한다. 대량의 데이터를 처리하기 위해서 물리적 노드들은 두 개 이상의 컴퓨터 시스템으로 구성이 되며 데이터 처리량에 따라서 노드가 늘어나거나 줄어들게 된다. Consistent Hasing를 사용하면, 서버가 추가되거나 삭제되더라도 최소한의 키 들만 재배치되도록 할 수 있다. Consistent Hashing는 분산 시스템, 데이터 파티셔닝, 데이터 복제등에서 중요하게 사용한다. 자세한 내용은 [Consistent Hashing]([https://www.joinc.co.kr/w/man/12/hash/consistent](https://www.joinc.co.kr/w/man/12/hash/consistent)) 문서를 참고하자. ## Quorum Quorum은 컴퓨터 시스템이 의사결정을 내리기 위한 "정족수(Quorum)"를 채우기 위해서 필요한 최소 요소의 수를 나타낸다. 분산시스템에서 Quorum은 데이터의 가용성과 일관성을 보장하기 위해서 사용한다. 예를 들어 분산 데이터베이스의 경우 어떤 데이터를 쓰기전에 정족수에 달하는 컴퓨터가 이에 합의를 해야 한다. 이는 서로 다른 컴퓨터들이 서로 다른 데이터 상태를 가지면서 충돌하는 **split-bran** 시나리오를 막는데 도움이 된다. Quorum은 일반적으로 Paxos 또는 Raft 같은 합의 알고리즘으로 구현한다. 컴퓨터 시스템은 장애가 생길 수 있는데, 장애가 생긴 시스템은 결정에 참여할 수 없다. 이렇게 일부 시스템을 사용할 수 없는 경우에도 이들 알고리즘을 이용해서 시스템이 계속 작동하도록 할 수 있다. 간단히 Quorum은 "의사결정 위원회"를 구성하고 유지하는 것이라고 보면 된다. Quorum에서 의사결정은 과반 즉, **(N/2 + 1)** 을 넘기면 된다. 따라서 클러스터는 홀수 3, 5, 7 ... 로 구성하면 된다. 예를들어서 3개의 시스템으로 구성된 클러스터의 경우 2대의 시스템이 가동 중이라면 이 클러스터는 작동하게 된다. 아래는 5개의 시스템으로 구성된 클러스터에서 Quorum이 어떻게 작동하는지를 보여주고 있다. 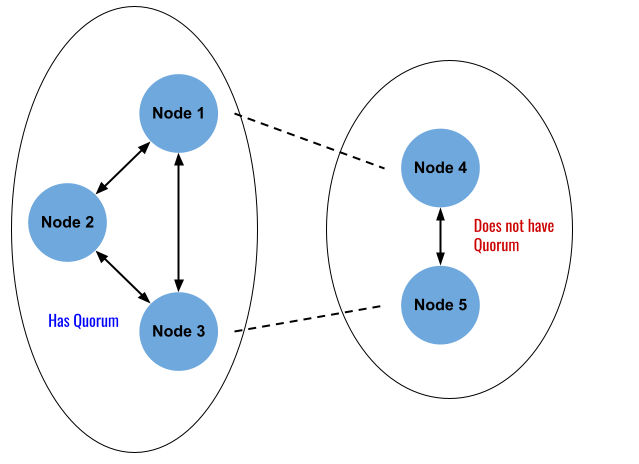 네트워크 장애가 발생해서 클러스터가 3:2로 분리되면 어떤일이 발생할까 ? 여기에서는 Node 1, Node 2, Nod 3이 다수를 구성하고 있으므로 이들이 클러스터가 되어서 계속 실행된다. 소수인 4, 5는 클러스터 실행이 중지된다. 네트워크가 복구가 되면 Node 4, Node 5는 자동으로 클러스터에 합류하게 된다. ## Checksum 분산 시스템의 구성요소 간에 데이터 교환이 일어날때, 데이터가 손상될 수 있다. 따라서 각 시스템은 **cheksum** 을 이용해서 데이터가 올바르게 전달됐는지를 검사한다. Checksum은 네트워크를 통해 전송되는 파일, 메시지와 같은 데이터의 무결성을 확인하는데 사용되는 값으로 고정된 작은 문자열로 구성된다. 데이터 수신자는 checksum 과 데이터를 비교하여서 데이터가 변경되거나 손상됐는지를 확인 할 수 있다. 아래는 checksum의 작동방식을 보여준다. 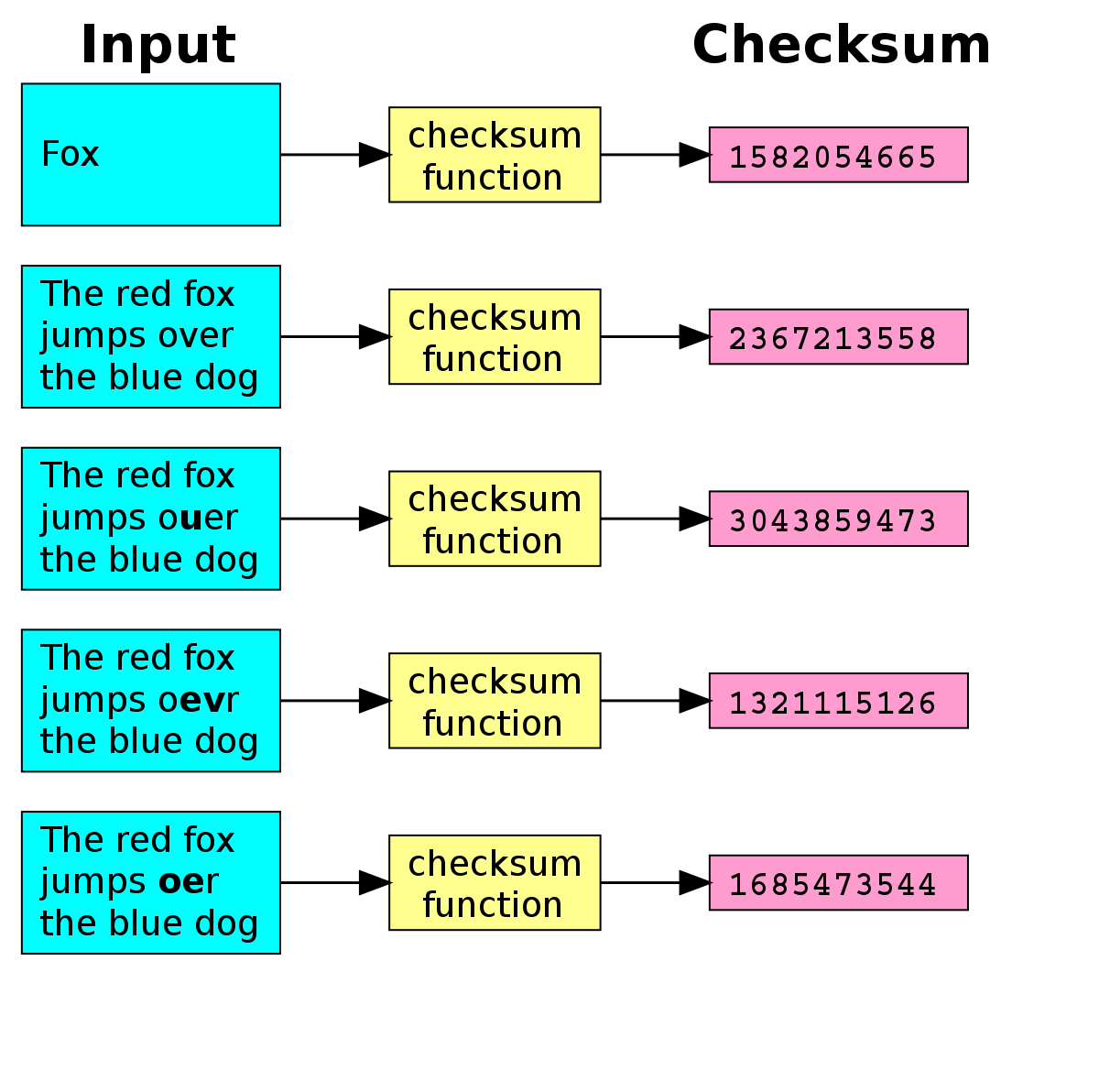 먼저 **checksum function** 을 만든다. 이 checksum function은 입력데이터에 특정한 연산을 해서 checksum value를 생성해낸다. 데이터 전송중에 문제가 생길면 checksum 값이 다를 테고, 시스템은 데이터에 문제가 생긴것을 확인 할 수 있다. 아래의 예를 보자. Hello World를 전송하기 위해서 "Hello World" 문자열로 checksum을 12345678을 만들었다. 송신측에서는 데이터의 끝 혹은 처음에 이 checksum을 함께 전달한다. 그런데 통신중에 문자열이 변조됐다. 수신측에서는 변조된 문자열 "Hello W!!!!"로 checksum을 만들어서 송신측에서 전송한 checksum과 비교한다. 수신측은 checksum 문자열이 다른 걸 확인하고 데이터가 변조되었음을 알 수 있다. 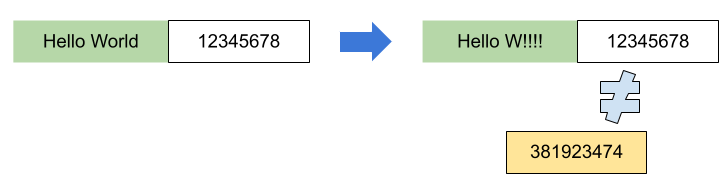 ## Leader election 분산 시스템은 여러개의 컴퓨터 시스템으로 구성이 되기 때문에 이들이 충돌을 피하고 일관된 상태를 유지하기 위한 조정작업이 필요하다. 시스템을 조율하고 구성하기 위한 이러한 작업은 **하나의 "선출된 시스템"** 이 수행하는게 일반적이다. 이를 위하여 분산 시스템에서 **Leader election** 이 매우 중요한 기능이다. 분산 시스템에서 Leader 가 하는 일은 다음과 같다. 1. 조정(Coordination) : 시스템의 모든 작업을 조정한다. 이를 위해서 리더는 등록된 시스템을 모니터링한다. 2. 합의(Consensus) : 히스템의 현재 상태에 대한 합의를 촉진하여 모든 시스템이 일관된 상태를 유지하도록 한다. 3. 작업할당(Task assignment): 데이터의 처리 저장등을 작업을 수행할 시스템을 선택해서 작업을 할당할 수 있다. 4. 장애감지(Failure detection) : 관리중인 시스템의 장애, 네트워크 장애를 감지하고 대응해야 한다. 예를들어 특정 시스템에 장애가 발생하면, 이 시스템을 식별해서 작업이 할당되지 않도록 해야 한다. 5. 로드밸런싱(Load balancing) : 특정 시스템에 부하가 걸리지 않도록 시스템 전체에 워크로드를 균등하게 분배한다. 이처럼 리더는 중요한 일을 맡고 있기 때문에 리더가 안정적으로 작동하게 하는 것도 중요하다. 그래서 하나 이상의 컴퓨터 시스템들로 구성된 리더 그룹이 만들어지며, **Leader election** 알고리즘을 이용해서 이 중 하나의 시스템이 리더가 되도록 한다. 리더 그룹은 하나의 Leader 와 하나 이상의 follower로 구성이 되며, 만약 Leader에 장애가 발생하면, follower 중 하나가 Leader로 선출된다. Leader election에는 주키퍼(zookeeper)과 같은 분산 코디네이터 프로그램이 사용된다. # Database ## Relation database 관계형 데이터베이스는 행과 열로 구성된 테이블을 사용하여 구조화된 방법으로 데이터를 저장하는 데이터베이스 유형이다. 테이블은 키와 관계(Relation)을 통해 서로 연결되며 조직화된 방식으로 데이터를 쿼리하고 조작 할 수 있다. 관계형 데이터베이스의 주요 구성요소는 아래와 같다. 1. 테이블 : 데이터는 행과 열이 있는 테이블에 저장된다. 2. 관계 : 테이블은 키를 통해서 서로 관계를 맺는다. 3. 정규화 : 정규화란 데이터를 별도의 테이블로 구성하여 중복성을 최소화하고 데이터의 무결성을 향상시키기 위해서 사용하는 데이터베이스 설계 기술이다. 기본 원칙은 큰 테이블을 작은 테이블로 만들고 각 테이블간의 관계를 정의하여 데이터가 일관되고 효율적으로 저장되도록 하는 것이다. 4. ACID : 관계형 데이터베이스는 ACID(Atomicity, Consistency, Isolation, Durability)원칙을 준수하여 안정적인 트랜잭션과 데이터 무결성을 보장한다. 모든 인터넷 서비스 시스템에서 관계형 데이터베이스는 필수로 들어간다. 아래와 같은 주요 관계형 데이터베이스 시스템들이 있다. * MySQL * MariaDB * PostgreSQL * Oracle * SQLite ### SQL SQL(Structured Query Language)는 관계형 데이터베이스를 관리하고 조작하는데 사용하는 프로그래밍 언어다. SQL은 MySQL, PostgreSQL, Oracle, Microsoft SQL Server와 같은 관계형 데이터베이스 관리시스템의 표준 언어다. SQL을 소프트웨어 언어로 포함하는 경우 여전히 10위안에([TIBEO]([https://www.tiobe.com/tiobe-index/](https://www.tiobe.com/tiobe-index/))) 들어가는 인기있는 언어다. 백앤드 소프트웨어, DevOps, 데이터 엔지니어 / 과학자 라면 반드시 알고 있어야 하는 언어다. ### Join 관계형 데이터베이스 설계의 기본 원칙은 큰 테이블을 작은 테이블로 만들고 각 테이블간의 관계를 정의하는 것이다. 관계형 데이터베이스는 SQL의 **Join**을 이용해서 관계기반으로 데이터를 조회 할 수 있다. 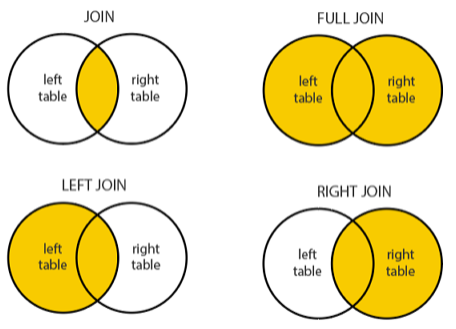 JOIN은 INNER JOIN, FULL JOIN, LEFT JOIN, RIGHT JOIN 등이 있다. ### Non-relation databases Non-relation 데이터베이스 혹은 no SQL 데이터베이스는 구조화되지 않는 형태로 데이터를 저장하는 데이터베이스들을 의미한다. NoSQL 데이터베이스는 관계형 데이터베이스에서 모델링하기 어려운 텍스트, 이미지, 소셜 미디어 데이터와 같은 대량의 비정형 또는 반정형 데이터를 효과적으로 처리하도록 설계되었다. 처리하려는 데이터에 따라서 Key/Value 데이터베이스, Graph 데이터베이스, Document 데이터베이스와 같은 다양한 접근 방식을 제공한다. 관계형 데이터베이스와 비교하여 NoSQL 데이터베이스의 특징은 다음과 같다. 1. 데이터 구조 : NoSQL 데이터베이스는 문서, Key/Value, Graph, column 기반과 같은 다양한 데이터 구조를 사용한다. 반면 관계형 데이터베이스는 tabular 구조를 사용한다. 2. 확장성 : NoSQL 데이터베이스는 수평적확장을 위해 설계되어 요청이 증가할 때 노드를 쉽게 추가할 수 있다. 반면 관계형 데이터베이스들은 수직적으로 확장하도록 설계되었기 때문에 요청이 증가하는 경우 하드웨어를 업그레이드 한다. 3. 유연성 : NoSQL 데이터베이스는 데이터 구조를 자유롭게 변경할 수 있는 동적 스키마를 사용한다. 관계형 데이터베이스는 고정 스키마를 사용한다. 4. 일관성 : NoSQL 데이터베이스는 최종 일관성을 제공한다. NoSQL은 분산 시스템 아키텍처를 사용하는데, 모든 컴퓨터 시스템에서 데이터가 즉각적인 일관성을 제공하지 않고 일정시간이 지난후에 일관성을 제공할 수 있다. 반면 관계형 데이터베이스는 모든 시스템에서 즉각적으로 일관성을 달성한다. 5. 트랜잭션 : NoSQL 데이터베이스는 트랜잭션을 제한적으로 지원하는 반면 관계형 데이터베이스는 ACID 트랜잭션을 지원한다. 6. 쿼리 : NoSQL 데이터베이스는 복잡한 쿼리에 대한 지원이 제한적인 반면 관계형 데이터베이스는 Join, 서브 쿼리등 다양한 쿼리 옵션을 제공한다. 7. 성능 : NoSQL 데이터베이스는 일반적으로 대량의 비정형 데이터를 처리하는데 나은 성능을 보이는 반면 관계형 데이터베이스는 정형 데이터 및 복잡한 트랜잭션에서 더 나은 성능을 보인다. 아래와 같이 다양한 종류의 데이터베이스들이 존재한다. 1. Document 데이터베이스 : MongoDB, CouchDB 2. Key-Value 데이터베이스 : Redis, Riak 3. Column 데이터베이스 : Cassandra, Hbase, 4. Graph 데이터베이스 : Neo4j, OrientDB 5. XML 데이터베이스 : BaseX, eXist-db ### 정형데이터 vs 비정형데이터, vs반정형 데이터  자세한 설명 참조 [Data Types](https://joinc.co.kr/w/full-text-serach) | | 정형 데이터 | 반정형 데이터 | 비정형 데이터 | | -------- | ------------------------------------- | ------------------------------ | ------------------------------------- | | 기술 | 관계형 데이터베이스 | XML,RDF,JSON | 텍스트, 바이너리 데이터 | | 트랜잭션 | 성숙한 트랜잭션 및 다양한 동시성 기술 | RDBMS에 비해서 제한된 트랜잭션 | 지원하지 않음 | | 유연성 | 엄격한 스키마 | 유연하고 관대한 스키마 | 매우 유연하며 스키마가 없을 수도 있음 | | 확장성 | DB 스키마 확장이 어렵다 | 간단한 스키마 확장 | 매우 쉽게 확장 | | 견고성 | 매우 견고함 | 다양한 수준의 견고함 | - | | 쿼리 성능 | 복잡한 Joinc의 허용 | 익명노드에 대한 쿼리 가능 | 텍스트 기반의 쿼리만 가능 | ### Data Lake & Data Warehouse 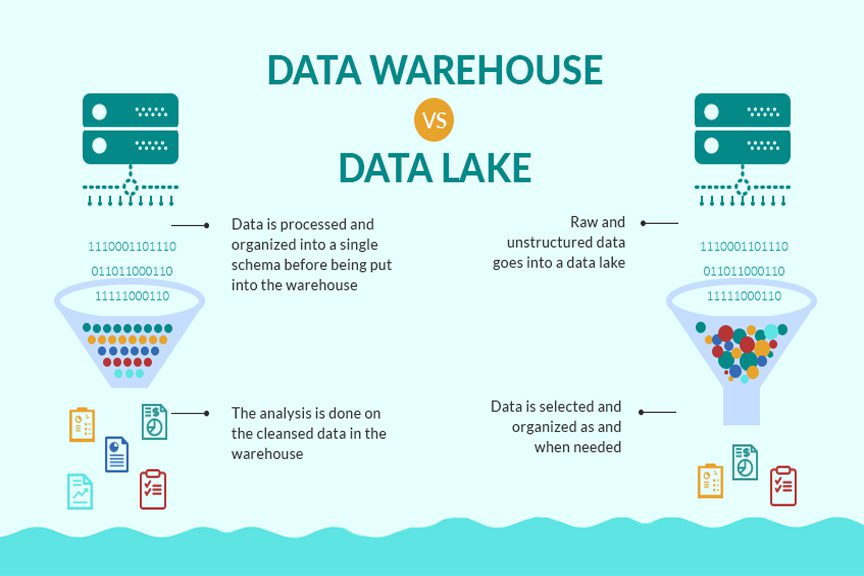 데이터 레이크(Data Lake)는 모든 규모의 정형, 비정형, 반정형 데이터를 저장 할 수 있는 중앙집중식 데이터 저장소다. 보통 데이터 레이크에는 데이터를 있는 그대로 저장하고 그 후에 빅데이터 처리, 머신러닝 등에 이르는 다양한 분석을 실행한다. 빅데이터를 처리 할 때, MapReduce 기술은 보편적으로 사용한다. 데이터 웨어하우스(data warehouse)는 다양한 소스에서 발생하는 데이터를 표준화하고 조직화된 형식으로 저장하여 대량의 데이터에서 패턴, 관계를 분석하기 위해서 사용한다. 데이터 웨어하우스는 데이터 마이닝, OLAP 및 보고서와 같은 비즈니스 인텔리전스 활동을 지원하도록 설계되었으며 일반적으로 데이터 기반 의사결정을 위한 도구로 사용한다. 데이터 레이크와 데이터 웨어하우스를 비교한 표를 참고하자. | 요소 | 데이터 웨어하우스 | 데이터 레이크 | | ----------- | -------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | | 데이터 | 트랜잭션 시스템, 운영 중인 데이터베이스 | IoT장치, 웹 사이트, 모바일 앱, 소셜미디어 및 기업 애플리케이션에서 발생하는 비 관계형 혹은 관계형 데이터들 | | 스키마 | DW 구현 이전에 설계한다.(schema-on-write) | 분석 시 작성(schema-on-read) | | 성능 | 더 높은 비용의 스토리지를 사용하여 가능한 빠른 쿼리 결과 | 비교적 저 비용 스토리지를 사용하여 더 빨라지는 쿼리 | | 데이터 품질 | 잘 정돈된 선별된 데이터 | 선별된 혹은 선별하지 않은 모든 데이터 즉 원시 데이터 | | 사용자 | 비즈니스 전문가 | 데이터 과학자, 데이터 개발자 및 비즈니스 분석가 | | 분석 | 배치작업, BI와 시각화 | 기계학습, 예측 분석, 데이터 검색 및 프로파일링 | ### REDIS REDIS는 최근 수년동안 많은 인기를 얻고 있는 오픈소스 인메모리 데이터 저장소다. 데이터베이스, 캐시 및 메시지 브로커 등 다양한 용도로 사용할 수 있는 다목적 도구다. Redis는 string, Hash, List, Sets, Bitmap, Hyperloglog, Geospatial 등 다양한 데이터 구조를 지원한다. 이러한 다양한 데이터 구조 덕분에 광범위한 애플리케이션에 사용되고 있다. Redis는 모든 데이터를 메모리에 저장하기 때문에 디스크에 의존하는 다른 데이터베이스에 비해서 훨씬 빠른 성능을 제공한다. 따라서 Redis는 빠른 데이터 검색, 업데이트가 필요한 실시간 분석에 이상적인 솔류션이다. [Redis Data modeling](https://www.joinc.co.kr/w/man/12/REDIS/DataModeling) 에서 다양한 Redis 데이터 구조와 사용예제를 확인 핧 수 있다. ### 샤딩 & 파티셔닝 샤딩(Sharding)은 데이터베이스의 가용성, 성능 그리고 확장성을 높이기 위해서 여러 서버에 데이터를 분산하는 데이터베이스 파티셔닝 기술이다. 여기에서는 하나의 큰 데이터베이스를 샤드라고 하는 더 작고 관리하기 쉬운 조각으로 나누는 작업이 포함된다. 각 샤드는 별도의 서버에 저장되기 때문에 1. 여러 서버로 로드를 분선할 수 있으며 2. 더 작은 데이터베이스에서 검색이 가능하므로 성능을 향상 시킬 수 있다. 샤딩을 사용하면 여러 서버가 데이터 요청을 병렬로 처리할 수 있으므로 특히 읽기가 많은 서비스의 성능을 크게 향상시킬 수 있다. 범위기반 샤딩, 해시기반 샤딩, 디렉토리 기반 샤딩등 다양한 방식이있다. 샤딩에 대한 자세한 내용은 [데이터베이스 샤딩](https://www.joinc.co.kr/w/database_shard) 문서를 참고하자. ### Database Indexing 데이터베이스 색인(Indexing)을 사용하면 테이블에서 원하는 행이나 열을 더빠르게 찾을 수 있다. 색인을 하면 데이터베이스의 모든 행을 검색하지 않고도 원하는 값을 찾을 수 있다. 데이터베이스 관리자는 데이터베이스 테이블에 색인을 위한 별도의 컬럼을 생성할 수 있다. **빠른조회** 선형검색(linear search) 각 행의 처음부터 순차적으로 검색하는 방식이다. 대규모 데이터베이스에서는 매우 비효율적이기 때문에 모든 데이터베이스 소프트웨어는 색인 기술을 포함하고 있다. **데이터베이스 제약 조건 감시** 색인은 UNIQUE, EXCLUSION, PRIMARY KEY, FOREIGN KEY와 같은 데이터베이스 제약조건을 감시하는데 사용한다. 예를 들어 유일한 값이 존재해야 하는 조건은 UNIQUE로 선언이 되는데, 색인을 기본으로 포함한다. 색인이 되지 않을 경우 유일한지를 확인하기 위해서 전체 행을 모두 검사해야 할 수 있기 때문이다. FOREIGN KEY 제약조건도 마찬가지다. 색인을 해야 해당 제약조건을 만족하는지를 빠르게 검사할 수 있기 때문이다. 데이터가 늘면서 시스템이 느려지는 경우 색인을 하지 않는 경우가 다반사일 정도로 서비스 성능에 중요한 영향을 미친다. 색인은 별도의 컬럼을 생성하기 때문에 데이터베이스의 크기가 그만큼 커질 수 있다. 따라서 색인은 필요한 곳에만 써야 한다. # 분산 시스템 ## Map & Reduce **MapReduce**는 대규모 데이터세트를 처리하고 분석하기 위한 병렬분산 알고리즘이다. MapReduce는 구글에서 개발했으며 빅 데이터 문제를 작은 데이터로 분할하여 클러스터의 여러 노드에서 동시에 해결 할 수 있도록 했다. 이렇게 여러 노드에 분산되어서 처리된 결과물들은 나중에 다시 통합하여서 최종 결과를 생성한다. MapReduce의 작동방식은 다음과 같다. 이해하기 쉽게 문서에 포함된 단어를 카운팅하는 예제를 만들었다. 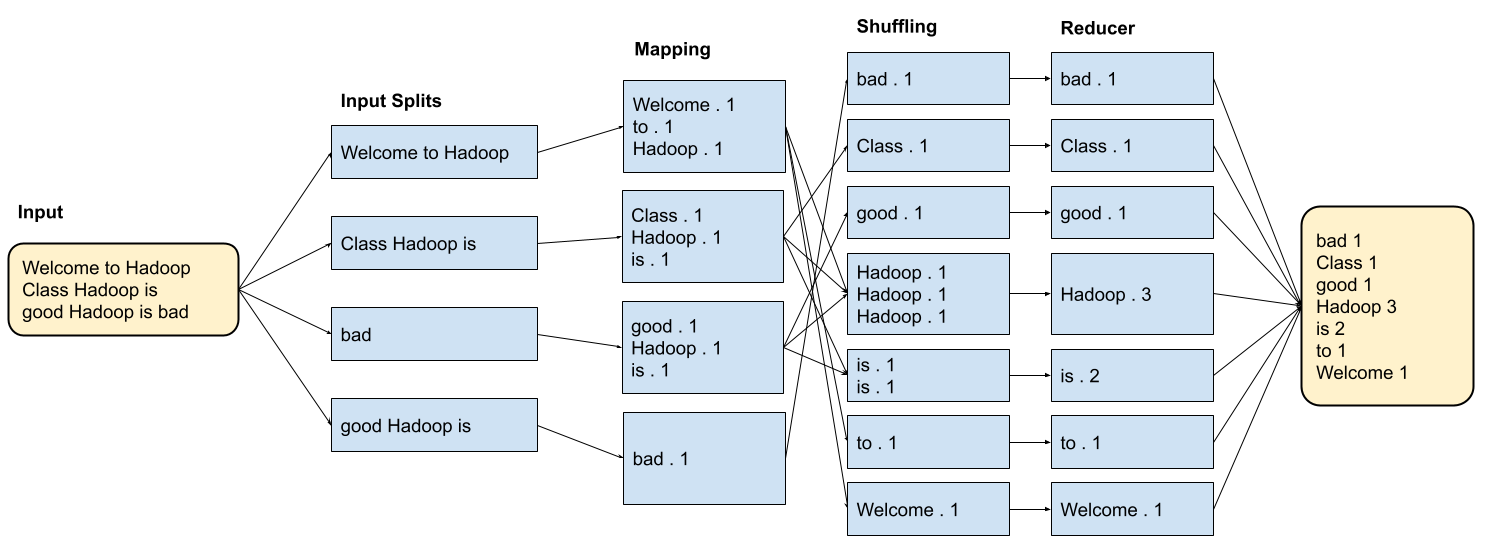 1. Map : 입력데이터는 작은 청크(chunk)로 분할되어 Mapper로 전달된다. 각 mapper는 할당받은 데이터 청크 하나를 처리하고 중간 결과를 출력한다. 예제에서는 입력 문장을 더 작은 단위로 나눠서 mapper로 전달했다. mapper는 전달받은 문장에서 단어를 추출하고 count를 한다. 2. Shuffle : mapper 함수의 중간 결과를 shuffle하고 정렬해서 동일한 key를 가진 값들을 동일한 reducer 함수로 전송한다. 예제에서 key는 추출한 단어가 된다. 3. Reducer : 중간결과를 처리해서 최종 결과물을 출력한다. ## Stateless & Stateful 상태저장(Stateful)과 상태비저장(Stateless)는 분산시스템에서 중요하게 다루는 개념이다. 상태비저장 시스템은 과거 이벤트(혹은 작업)의 상태 정보를 유지하지 않는다. 지금 제공한 입력 값만을 가지고 실행된다. 상태저장 시스템은 이전 상태의 값을 유지한다. 즉 지금 입력 값 뿐만아니라 이전 상태 값도 읽어서 데이터를 처리한다. 상태저장 시스템은 현재와 과거의 상태를 유지하기 때문에, 이전 상태와 상호작용을 하면서 요청을 처리할 수 있다. 전자 상거래 서비스의 카트는 가장 대표적인 상태저장 시스템이다. 카트에 상품을 저장하기 위해서 시스템은 "사용자가 로그인했는지와 상품 구매이력등을 추적"할 수 있어야 한다. 반면 상태 비저장 시스템은 이전 상태나 이벤트를 전혀 기억하지 않는다. DNS(Domain Name System)은 도메인 이름을 IP 주소로 변환하는 시스템이다. 각 개별적인 IP 주소 변환 요청은 이전 요청과 (아무런 상관없이) 독립적으로 실행되는 상태비저장 시스템이다. HTTP 역시 상태비저장 시스템이다. HTTP의 각 요청은 이전 요청과 별개로 작동한다. 일반적으로 상태저장 시스템은 상태비저장 시스템에 비해서 복잡하며, 규모를 키우는데 많은 어려움이 따른다. 상태를 저장하기 위한 저장공간과 상태를 검색하기 위한 검색 시스템등이 필요하기 때문이다. 상태비저장 시스템은 서버만 추가하면 되기 때문에 매우 간단하게 규모를 키울 수 있다. ## Raft Raft 알고리즘은 분산 시스템에서 여러 노드간 합의를 하기 위해서 사용하는 합의 알고리즘이다. 같은 목적으로 사용하는 Paxos 보다 이해하기 쉬워서 널리 사용하고 있다. Raft는 단일노드를 리더로 선택하도록 한다.  Raft에서 리더 선택은 분산 시스템의 노드 간에 일관된 상태를 유지하기 위한 중요한 프로세스로 아래와 같은 프로세스에 따라서 리더를 선출한다. 1. 모든 노드를 후보로 초기화: 노드가 시작되거나 현재 리더가 실패하면 후보가 되어 새로운 선거 기간을 시작합니다. 2. 투표 요청: 후보는 투표 요청 메시지를 전송하여 다른 노드에 투표를 요청합니다. 노드는 기간당 한 번만 투표할 수 있으며 요청한 첫 번째 후보에게만 투표합니다. 3. 다수 확보: 리더가 되려면 후보가 다수 투표(즉, 노드의 절반 이상)를 얻어야 합니다. 후보자가 과반수를 얻으면 현 임기의 지도자가 됩니다. 4. 리더 모니터링: 모든 노드는 리더가 계속 살아 있는지 확인하기 위해 지속적으로 모니터링합니다. 리더가 실패하면 노드는 새 리더를 선출하기 위해 새로운 선거 기간을 시작합니다. # 확장 가능한 웹 애플리케이션 ## DNS 와 Load Balancing 인터넷에 연결된 컴퓨터는 IP 주소를 가져야만 한다. 하지만 IP주소는 111.222.333.444와 같은 숫자 기반이라서 사용하기가 쉽지 않다. **DNS(Doman Name System)** 은 도메인 이름을 IP 주소에 맵핑하여 인터넷에서 서비스를 쉽게 사용 할 수 있도록 돕는 시스템이다. 도메인 이름에는 하나 이상의 서버를 맵핑 할수 있기 때문에 DNS를 이용한 로드밸런싱도 가능하다. 인터넷 비즈니스의 규모가 커지면서 컴퓨터 시스템의 확장도 매우 중요한 이슈가 됐다. 시스템 확장에서 가장 중요한 역할을 하는 하나를 선택하라면 단연코 로드밸런서(Load Balancer)일 것이다. 로드밸런서는 기본적으로는 **리버스 프록시**의 형태로 작동한다. 즉 인터넷 사용자들과 인터넷 서버의 중간에 위치해서 인터넷 사용자의 요청을 읽어서 서버로 전달하는 일을 한다. 로드밸런서는 N 개의 서버로 요청을 **분산해서 라우팅** 할 수 있는 기능을 가지고 있다. 사용자 요청이 늘어나면 로드밸런서 밑에 서버를 추가하면 된다. 그러면 로드밸런서는 자동으로 해당 서버로 요청을 분산하게 된다. 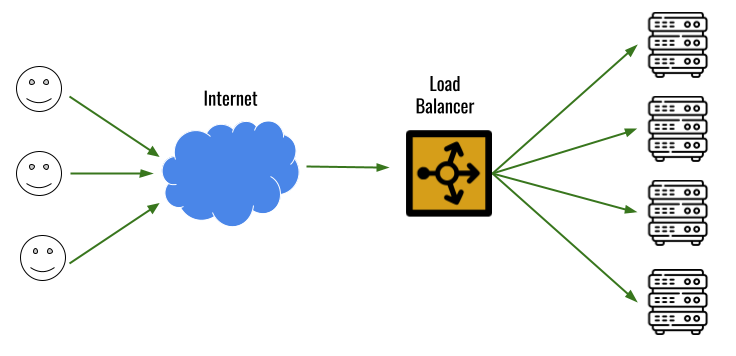 예전에는 시스템 운영자가 서버를 구매하고 추가 한 다음, 로드밸런서 설정을 바꾸는 등의 작업을 해야 했지만 클라우드에서는 모든 것을 자동으로 처리한다. 로드밸런서는 다루는 OSI Layer에 따라서 L4와 L7 유형이 있다. 1. L4 : OSI Layer 4인 전송계층(Transport Layer) 프로토콜을 다룬다. 대표적인 프로토콜은 TCP/UDP 이다. 즉 IP와 PORT를 기반으로 로드밸런싱을 한다. 2. L7 : OSI Layer 7인 응용계층(Application Layer) 프로토콜을 다룬다. 즉 HTTP의 데이터를 읽어서 라우팅을 할 수 있다. ### HTTP HTTP는 Hypertext Transfer Protocol의 약자로 WWW(World Wide Web)의 핵심 데이터 통신 프로토콜이다. HTTP는 요청 / 응답 기반의 프로토콜이다. 클라이언트인 웹 브라우저가 웹 서버에 "요청"을 하면 웹 서버는 요청을 분석해서 응답을 한다. HTTP는 상태비저장 프로토콜이다. 각 요청은 이전 요청들과 완전히 독립적으로 작동한다. 쇼핑몰같은 서비스는 사용자의 로그인 상태, 카트상태 등을 저장해야 한다. 인터넷 서비스들은 쿠키(Cookie) 와 데이터베이스를 이용해서 이 문제를 해결한다. 쿠키는 HTTP 요청에 삽입할 수 있는 데이터 조각이다. 이 쿠키에 맵핑되는 사용자 정보, 카트정보등을 저장한 데이터베이스를 이용해서 상태를 관리한다. 1996년 HTTP 1.0이 만들어진 이래로 1999년 1.1, 2015년 2.0이 만들어졌다. 2023년 현재 3.0 버전이 진행중에 있다. | 버전 | 도입년도 | 현재 상태 | | -------- | -------- | --------- | | HTTP/0.9 | 1991 | 구식 | | HTTP/1.0 | 1996 | 구식 | | HTTP/1.1 | 1997 | 기준 | | HTTP/2 | 2015 | 기준 | | HTTP/3 | 2022 | 기준 | HTTP/1.0과 비교하여 HTTP/1.1의 주요 특징은 다음과 같다. * HTTP/1.1은 **persistent connections**를 지원한다. 하나의 TCP 연결을 통해서 여러 요청을 보낼 수 있으므로 성능이 향상된다. * HTTP/1.1은 **chunked transfer**를 지원한다. 큰 응답을 더 작은 청크로 전송할 수 있어서 수신자가 응답을 완전히 수신하기 전에 데이터 처리가 가능하다. * HTTP/1.1은 **Host 헤더**를 도입하여 단일 서버가 여러 도메인을 호스트 할 수 있도록 했다. * HTTP/1.1은 캐시관리를 위해서 if-Modified-Since 헤더를 도입했다. 특정시간 이후 리소스가 수정되었는지를 서버에게 물어보고, 수정이 안됐다면 컨텐츠를 재 전송하지 않게 하여 송/수신 되는 데이터의 양을 줄일 수 있다. 클라이언트는 로컬에 있는 데이터를 사용하기 때문에 응답성이 향상된다. ## REST & RESTful REST는 프로토콜이나 표준이아닌 아키텍처 모델로 웹 서비스를 구축하기 위한 아키텍처 스타일을 제공한다. RESTful은 REST 원칙을 따르는 시스템 또는 애플리케이션을 나타낸다. 즉 REST 아키텍처 스타일을 따라서 작성한 애플리케이션을 RESTful 이라고 한다. 예를들어 RESTful API는 API를 RESTful에 따라서 만든 것이다. REST는 HTTP를 기반으로하는 아키텍처링 원칙이다. URL을 이용해서 작업할 자원(resource)의 위치를 설정하고 HTTP의 메서드인 **GET, POST, DELETE, PUT** 을 이용해서 작업방식을 지정할 수 있다. GET은 조회, DELETE는 삭제, POST는 생성, PUT은 업데이트를 위해 사용한다. 또한 데이터는 HTTP Body로 전송 할 수 있다.  REST는 아래와 같은 장점을 가지고 있다. * 확장성(Scalability) : REST는 HTTP 프로토콜을 기반으로 하기 때문에 쉽게 사용할 수 있다. 또한 L7 로드밸런서를 이용 할 수 있기 때문에 성능과 확장성의 확보가 용이하다. * 이식성 : RESTful 웹 서비스는 스마트폰, 태블릿 및 기존 웹브라우저를 포함한 다양한 장치 와 플랫폼에서 쉽게 사용 할 수 있다. 웹의 근간인 HTTP를 기본으로 하고 있기 때문이다. * 모듈성 : RESTful 웹 서비스는 쉽게 모듈화를 할 수 있으며,개발, 테스트, 유지관리가 용이하다. * 상태비저장 : RESTful 은 상태 비저장이다. 구현이 쉽고, 서비스의 안정성을 높일 수 있다. * 상호운용성 : RESTful 웹 서비스는 표준 HTTP 메서드를 사용하며 JSON, XML과 같은 표준 형식으로 데이터 통신을 할 수 있으므로 다른 시스템 및 서비스와 쉽게 통합할 수 있다. ## N-Tier Application N-Tier 애플리케이션은 **여러 계층으로 나눠서 설계**하는 소프트웨어 개발에 대한 접근방식이다. N-Tier 아키텍처는 확장성, 보안, 관리성, 성능, 유연성등에서 큰 이점이 있기 때문에 기업환경에서 널리 사용하고 있다. N-Tier 애플리케이션은 일반적으로 아래의 계층을 공통으로 포함한다. 1. 프리젠테이션 계층(Presentation Tier) : 웹 페이지 또는 GUI와 같은 "사용자에게 정보를 제공하는" 인터페이스를 제공한다. Frontend 영역이라고 할 수 있다. 2. 애플리케이션 계층(Application Tier) : 비즈니스 로직을 처리한다. 데이터 계층과 프리젠테이션 계층 중간에서 서로의 상호작용을 조정한다. Backend 영역이라고 할 수 있다. 3. 데이터 계층 : 데이터베이스, 파일 시스템등 데이터의 저장, 검색, 관리를 담당하는 계층이다. 각 계층은 물리적으로 분리될 수 있으므로 계층간 보안을 통해서 안정성을 확보할 수 있다. 또한 각 계층을 독립적으로 관리 할 수 있기 때문에 다른 계층과 상관없이 유연하게 기능을 업데이트 할 수 있다. 아래는 3-Tier 애플리케이션을 묘사하고 있다. 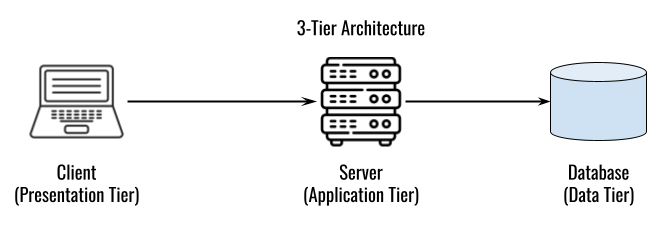 ## Caching 캐시(Cache)는 데이터에 빠르게 접근할 수 있도록 임시로 데이터를 저장하는 방법으로 하드웨어 혹은 소프트웨어를 이용해서 구현한다. 캐시는 메모리를 사용하는 경우가 많으며, 검색에 최적화된 간단하고 효과적인 알고리즘을 사용해서 성능을 극대화 시킨다. 예를들어 **REDIS**와 **Memcache**의 경우 메모리에 데이터를 저장하며 Key/Value 방식으로 데이터를 저장해서 빠르게 데이터에 접근 할 수 있게 한다. 예를들어 클라이언트가 자신의 프로파일(profile)에 접근해야 한다고 가정해보자. 프로파일의 원본은 서버의 데이터베이스에 저장되어 있을 것이다. 클라이언트의 요청은 캐시서버가 먼저 받는다. 만약 캐시서버에 프로파일이 있으면 데이터베이스를 조회하지 않고 즉시 반환한다. 캐시서버에 프로파일이 없으면, 데이터베이스를 조회해서 클라이언트에 전달하고 이때 캐시서버에 저장한다. 다음 요청부터는 데이터베이스를 조회하지 않고 캐시에서 바로 반환하게 될 것이다.  캐시의 장점은 아래와 같다. 1. 성능 향상 : 자주 사용하는 데이터를 캐시서버에 저장하면 클라이언트가 데이터에 더 빠르게 접근할 수 있으므로 전체 성능이 향상된다. 2. 지연시간 감소 : 캐시서버는 데이터 사본을 클라이언트에 보다 가까운 위치에 저장하기 때문에 접근시간을 줄일 수 있다. 3. 대역폭 감소 : 캐시 서버는 원본 서버에서 동일한 데이터를 다시 다운로드 할 필요를 없애기 때문에 대역폭의 양을 줄일 수 있다. 4. 가용성 증가 : 원본 데이터를 저장하는 데이터베이스에 문제가 생겨도, 캐시에 있는 사본으로 서비스를 할 수 있기 때문에 가용성을 증가 시킨다. 5. 비용 절감 : 원본 서버를 증설하지 않고도 성능을 향상 시킬 수 있기 때문에 전체 시스템의 비용을 줄일 수 있다. 6. 안정성 향상 : 복잡한 처리가 필요한 데이터베이스에 대한 요청이 줄어들기 때문에 시스템의 안정성이 향상된다. **Cache hit rate** 캐시 적중률(Cache hit rate)는 캐시의 효율성을 측정한 값이다. 캐시는 빠른 접근을 위해서 메모리를 사용한다. 메모리는 매우 비싼 장치이므로 자주 액세스하는 데이터들을 캐시하게 된다. 따라서 캐시를 사용하지 않고 디스크에 요청하는 경우가 생긴다. 캐시 적중률은 캐시가 제공하는 액세스의 백분율로 정의된다. 캐시 적중률이 높을 수록 디스크대신 캐시를 많이 사용하기 때문에 전체 시스템의 성능이 빨라질 것이다. **Cache eviction** 캐시 메모리 공간은 제한적이기 때문에, 공간이 가득차면 일부 데이터를 삭제해야 한다. 캐시 삭제를 위한 다양한 정책들이 있다. * FIFO(First In First Out) : 캐시에 가장 먼저 들어온 데이터 즉 가장 오래된 데이터를 삭제한다. * LIFO(Last In First Out) : 가장 마지막에 캐시된 데이터 즉 가장 최근 데이터를 삭제한다. * LRU(Least recently used) : 가장 오랜시간 사용하지 않는 데이터를 삭제한다. * MRU(Most recently used) : 가장 최근 사용한 항목을 삭제한다. * LFU(Least frequently used) : 가장 적게 사용한 데이터를 삭제한다. * RR(Random replacement) : 임의의 데이터를 선택해서 삭제한다. # Container 컨테이너(Container)는 **소프트웨어 코드를 종속성과 함께 패키징**하는 기술이다. 가상의 컴퓨터에서 운영체제와 소프트웨어를 VM(Virtual Machine)과는 상관이 없는 기술이다. 모든 컨테이너는 해당 호스트 운영체제 위에서 직접 실행되기 때문에 시스템 자원을 보다 효율적으로 사용할 수 있다. 기본적으로 컨체이너는 운영체제의 다른 프로세스와 동일하게 실행된다. 컨테이너 기술은 오픈소스 컨테이너 런타임인 **도커(Docker)** 가 등장하면서 널리사용되기 시작했다. 컨테이너는 소프트웨어를 실행하기 위한 모든 종속성이 함께 패키징되기 때문에, 개발환경과 배포환경을 통일 할 수 있다. 예를 들어 예전에는 워드프레스 실행환경을 만들려면 Apache, PHP, 데이터베이스 지식을 아진 엔지니어가 복잡한 과정을 거쳐서 설치하고 테스트해야 했다. 도커를 이용하면 아래와 같이 한번에 워드프레스를 실행할 수 있다. ```console $ docker run --name some-wordpress --network some-network -d wordpress ``` 이런 이유로 컨테이너를 기반으로 하는 시스템 설계가 인기를 얻고 있다. # Cloud 클라우드 컴퓨팅의 가장 중요한 특징은 "API를 이용하여 컴퓨터 시스템 / 네트워크 환경을 구축"할 수 있다는 점이다. 클라우드 컴퓨팅을 사용하면 사용자는 API 혹은 웹 브라우저를 이용해서 네트워크, 서버, 스토리지, 로드밸런서, 방화벽 등을 포함하는 완전한 데이터센터를 구축 할 수 있다. VM이 컴퓨터 서버의 가상화라면 클라우드 컴퓨팅은 데이터센터의 가상화라고 볼 수 있다. 클라우드는 다음과 같은 장점을 가지고 있다. **높은 확장성과 유연성** : 확장성은 필요할 때 리소스를 추가하여 증가하는 작업량을 처리할 수 있는 시스템 능력을 의미한다. 클라우드에서는 API 호출로(웹 브라우저에서 버튼 클릭) 수 분 안에 리소스를 추가할 수 있으므로 저장소, 처리능력을 쉽게 확장 할 수 있다. 유연성은 리소스를 수정하거나 재할당 할 수 있는 용이성을 나타낸다. 클라우드의 경우 물리적 하드웨어도 API로 제어할 수 있기 때문에 물리적으로 하드웨어를 재구성 할 필요 없이 빠르게 리소스를 할당, 재할당 및 조정할 수 있다. **비용 효율성**. 클라우드 컴퓨팅은 기존 온-프레미스 IT 시스템에 비해서 비용을 절감 할 수 있다. 이는 아래와 같은 여러 가지 방법을 통해서 달성 할 수 있다. 1. 종량제 가격 정책 : 클라우드는 실제 사용한 리소스에 대해서만 요금을 부과한다. 온-프레미스에서 필요한 초기 자본지출을 피할 수 있다. 또한 온-프레미스처럼 사용하지 않는 자원을 미리 구매해야 할 필요가 없다. 2. 유지관리 및 운영 비용 절가 : 클라우드 공급자가 인프라의 유지,보수,관리, 업그레이드를 책임지므로 조직은 이러한 작업에서 벗어날 수 있다. 3. 리소스 활용 능력 향상 : 클라우드에서는 수요에 따라 리소스를 동적으로 할당 및 해제할 수 있으므로 활용도를 극대화하고 낭비를 최소화할 수 있다. 4. 효율성 향상 : 클라우드 컴퓨팅은 물리적 하드웨어에 대한 유지관리, 업그레이드 및 지원의 필요성을 제거함으로써 IT 운영의 효율성을 높일 수 있다. **향상된 재해복구** 클라우드는 API를 이용해서 마치 소프트웨어를 실행하는 것처럼 빠르게 전개할 수 있다. 이러한 클라우드의 능력과 다양한 재해복구 솔류션을 이용해서 기존의 재해 복구 방법에 비해서 향상된 재해복구가 가능하며 재해가 운영에 미치는 영향을 최소화 할 수 있다. 예를들어 AWS는 RDS라는 데이터베이스 서비스를 이용한다. 이 서비스를 이용하면 사용자는 몇 번의 조작으로 **협업 및 생산성 향상**. 구체적으로 클라우드 환경에서는 아래와 같은 방식으로 생산성과 협업을 개선할 수 있다. 1. 인터넷을 통해서 클라우드 인프라, 데이터, 애플리케이션등에 원격으로 액세스 할 수 있다. COVID-19기간을 거치면서 인터넷을 통한 원격작업의 수요가 늘어나면서, 클라우드의 이런 특징이 각광을 받고 있다. 2. 단일 클라우드 계정에 중앙 집중식으로 데이터를 저장 및 관리 할 수 있다. 3. 자동화된 업데이트 및 유지관리로 적은 인원으로 더 많은 일을 할 수 있다. 4. 비즈니스의 요구사항에 즉각적으로 대응 할 수 있는 확장성과 유연성을 제공한다. 5. IT 인프라 및 지원 비용감소로 효율성, 비용절감이 증가한다. **광범위한 서비스와 기술에 대한 접근**. 클라우드는 데이터베이스, 스토리지, 컨테이너, 네트워크, 인프라, 머신러닝, AI, 빅데이터, 모바일, 보안, IoT, 캐시 등 IaaS, PaaS, SaaS 에 걸친 다양한 서비스를 제공한다. 따라서 조직은 다양한 기술들을 이용해서 비즈니스에 최적화된 시스템 및 서비스를 구축 할 수 있다. 아래는 AWS의 서비스를 정리한 그림이다. GCP와 AZURE도 수백여개에 넘는 광범위한 서비스들을 제공한다. 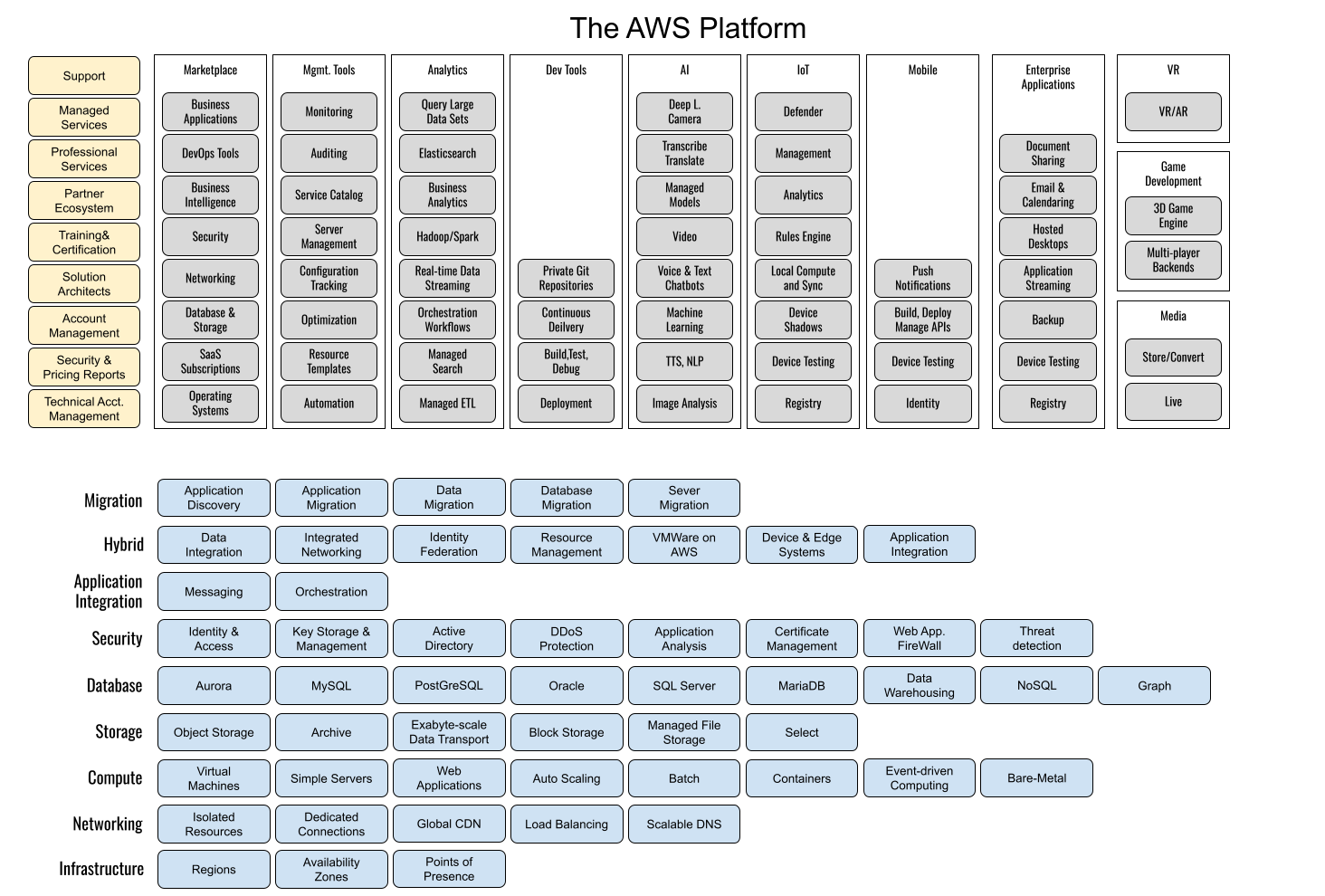 **자동화된 소프트웨어 업데이트**. .기존 온-프레미스에서는 소프트웨어 업데이트를 수동으로 수행해야 했기 때문에 시간이 오래걸리고 오류가 발생하기 쉬웠다. 물론 이러한 작업을 자동으로 하는 조직도 있기는 했으나 제대로 할 수 있는 기업은 많지 않았다. 클라우드는 소프트웨어를 자동으로 업데이트하여 관리하는 방식의 혁신을 이루어냈다. 사이버 보안 위협은 지속적으로 진화하고 있다. 클라우드는 보안 취약성을 해결하기 위해서 지속적으로 업데이트를 한다. 이러한 업데이트는 자동으로 진행되기 때문에, 고객은 항상 최신의 상태로 안전하게 시스템을 유지할 수 있다. 시스템 업데이트는 매우 어려운작업이다. 수동으로 진행되는 업데이트는 호환성 문제, 네트워크 문제등으로 올바르게 수행되지 않을 경우 시스템 오류로 이루어질 수 있다. 자동업데이트를 통해서 고객은 시스템업데이트와 관련된 부담에서 벗어나서 항상 최상의 시스템 버전을 유지하는데 도움이 된다. 이는 시스템의 전반적인 안정성을 향상시킨다. IT 팀의 업무량을 크게 줄일 수 있다. 소프트웨어를 수동으로 업데이트하는데 시간을 소비하는 대신, 네트워크관리, 자동화, 문제해결, 애플리케이션 개발과 같은 다른 중요한 작업에 집중할 수 있다. ## 참고 * [Software architecture vs design](https://www.lucidchart.com/blog/software-architecture-vs-design) * [Complete guide to system design](https://www.educative.io/blog/complete-guide-to-system-design) * [클라우드 아키텍처 센터](https://cloud.google.com/architecture/framework/system-design/principles?hl=ko)
Recent Posts
Vertex Gemini 기반 AI 에이전트 개발 06. LLM Native Application 개발
최신 경량 LLM Gemma 3 테스트
MLOps with Joinc - Kubeflow 설치
Vertex Gemini 기반 AI 에이전트 개발 05. 첫 번째 LLM 애플리케이션 개발
LLama-3.2-Vision 테스트
Vertex Gemini 기반 AI 에이전트 개발 04. 프롬프트 엔지니어링
Vertex Gemini 기반 AI 에이전트 개발 03. Vertex AI Gemini 둘러보기
Vertex Gemini 기반 AI 에이전트 개발 02. 생성 AI에 대해서
Vertex Gemini 기반 AI 에이전트 개발 01. 소개
Vertex Gemini 기반 AI 에이전트 개발-소개
Archive Posts
Tags
architecture
cloud
devops
Copyrights © -
Joinc
, All Rights Reserved.
Inherited From -
Yundream
Rebranded By -
Joonphil
Recent Posts
Archive Posts
Tags